Accounts Reconciliation
Accounts Reconciliation Financial Spreading
Financial Spreading Digital Archive
Digital Archive SchematicIQ
SchematicIQ Loan Ops
Loan Ops Docutwin
Docutwin Contract intelligence
Contract intelligence KYC/KYB
KYC/KYB Form Processing
Form Processing Investment Statements
Investment Statements Enterprise Knowledge
Agent
Enterprise Knowledge
Agent Realtime Intelligence
Realtime Intelligence Customer Support 360
Customer Support 360 Analytica
Analytica CreditIQ
CreditIQ City Intelligence
City Intelligence Smart Utilities
Smart Utilities Connected Worker & Assets
Connected Worker & Assets Drone Based Infra Monitoring
Drone Based Infra Monitoring SceneTrack
SceneTrack
























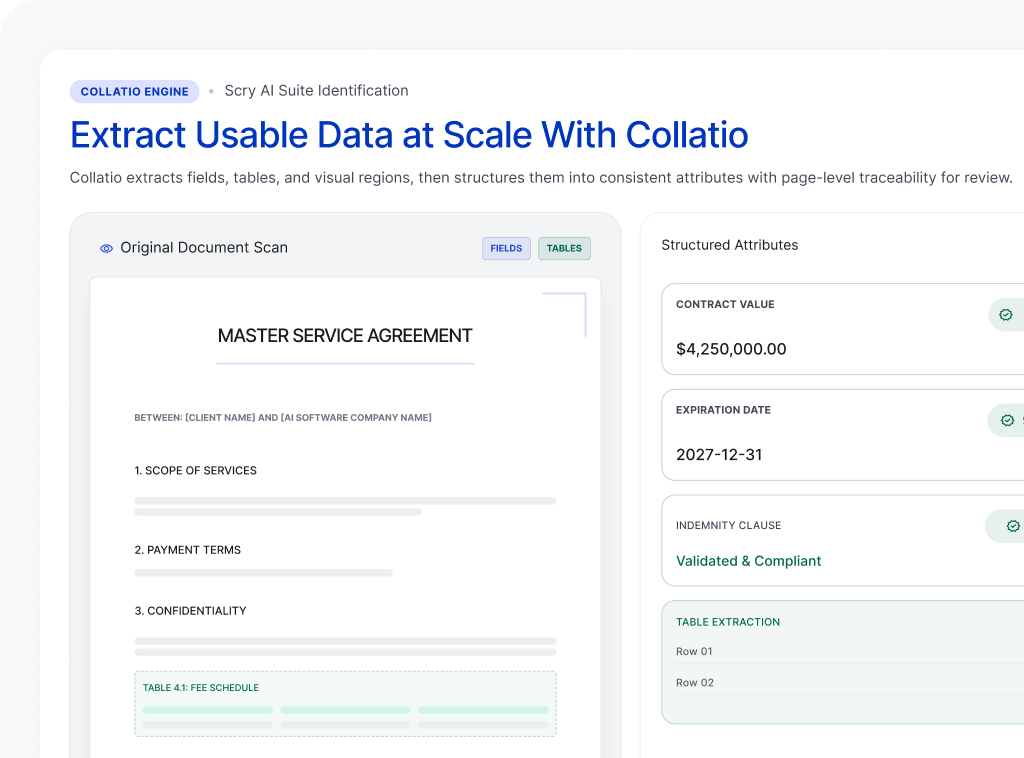
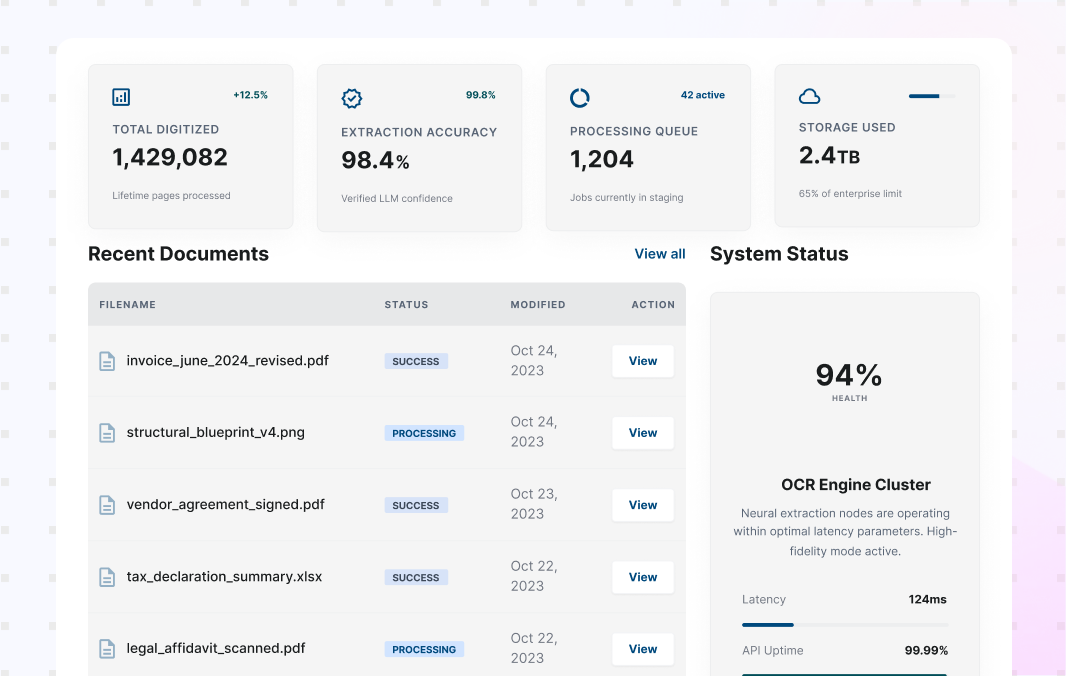
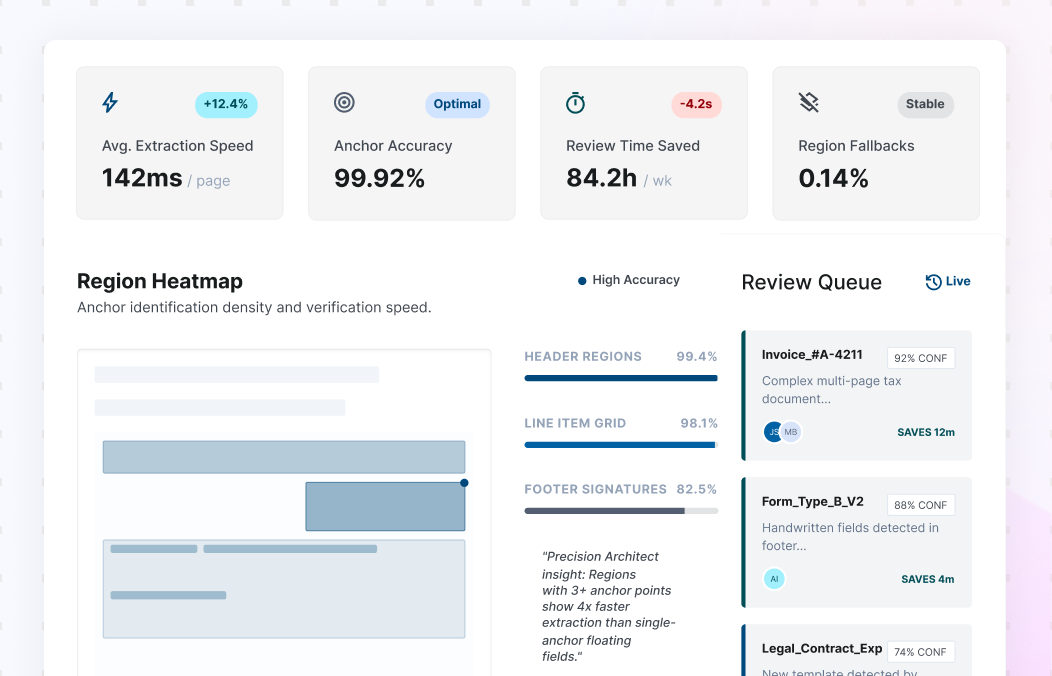
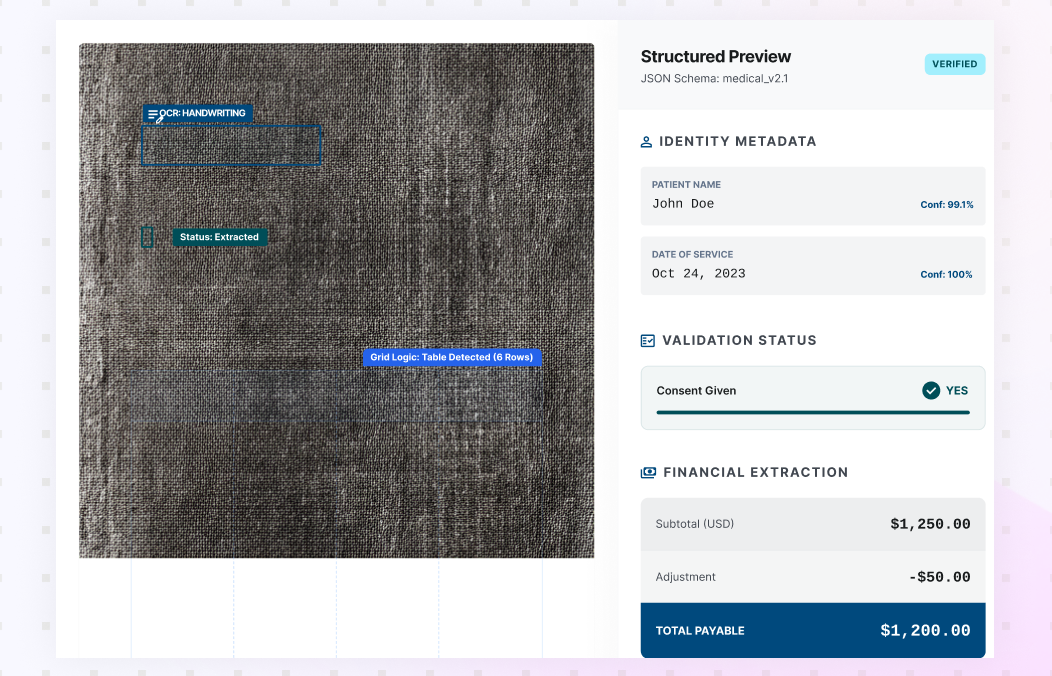
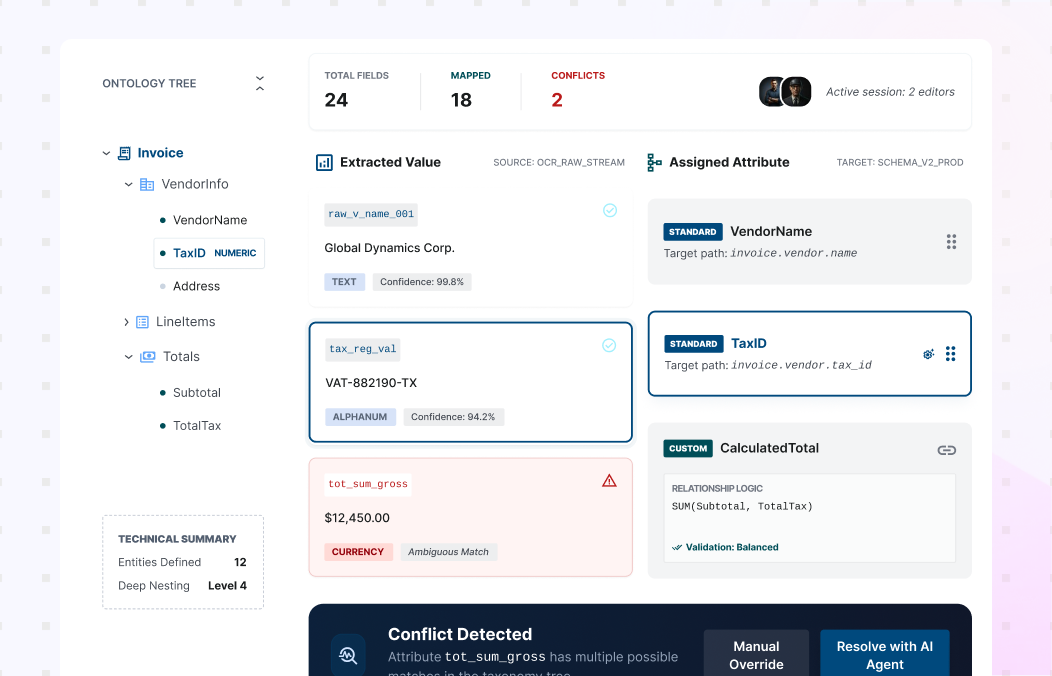
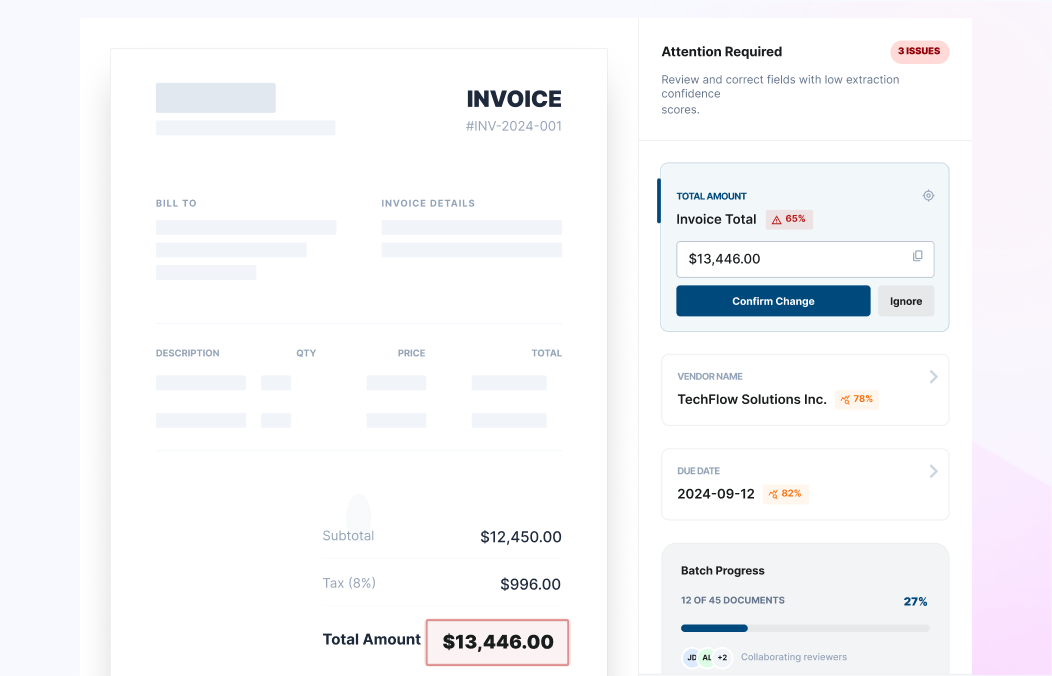
Document Data Extraction software for Enterprise Workflows
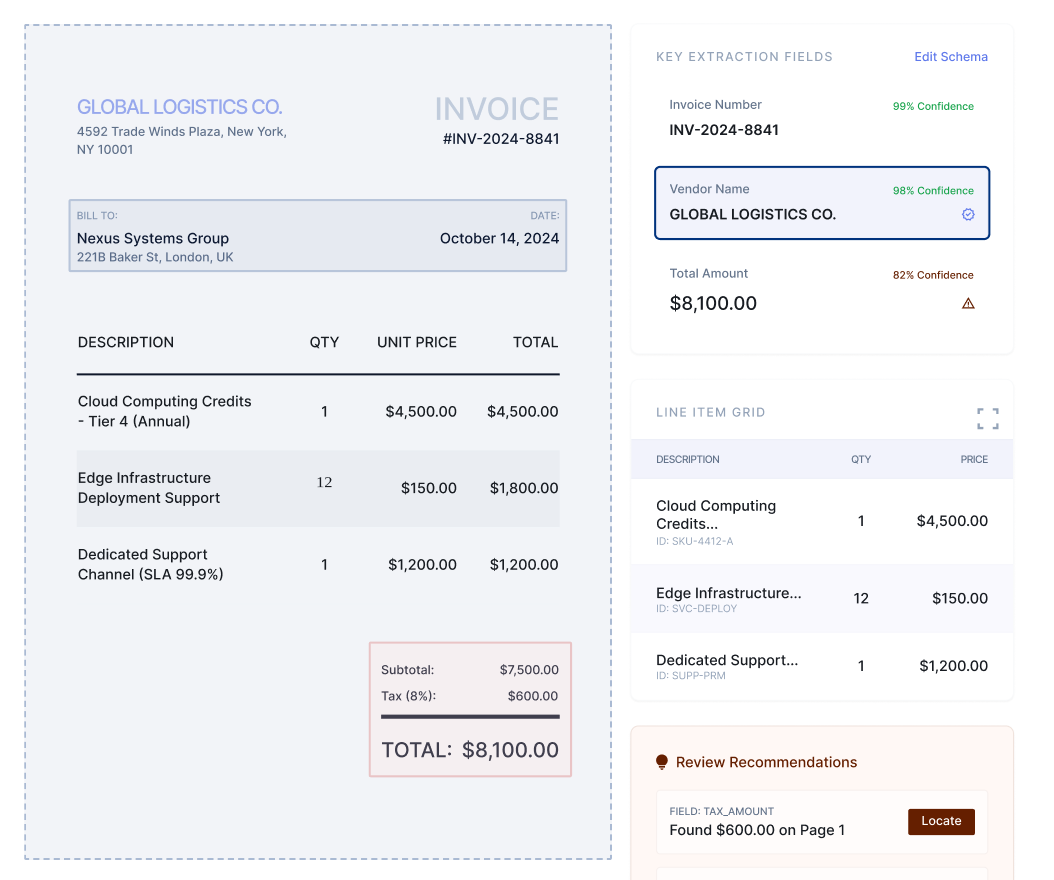
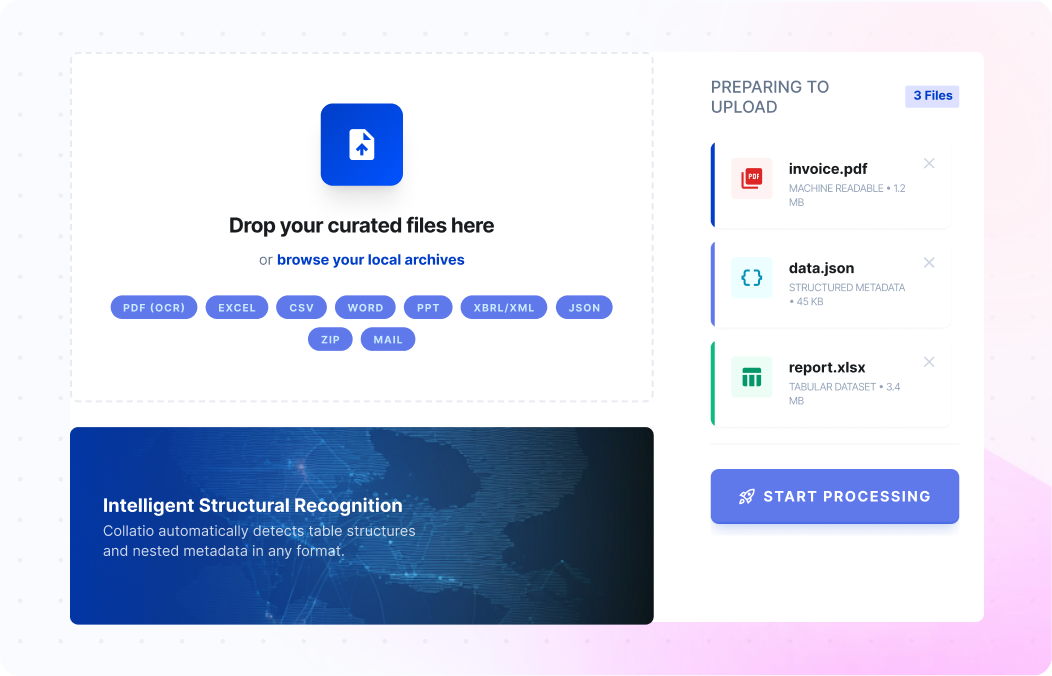
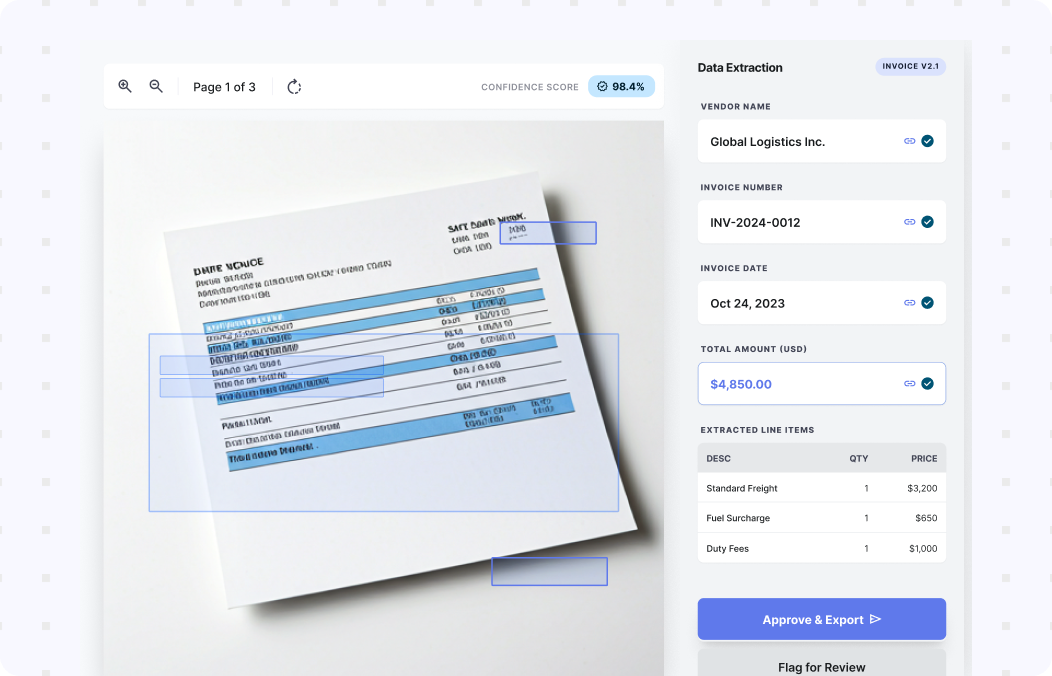
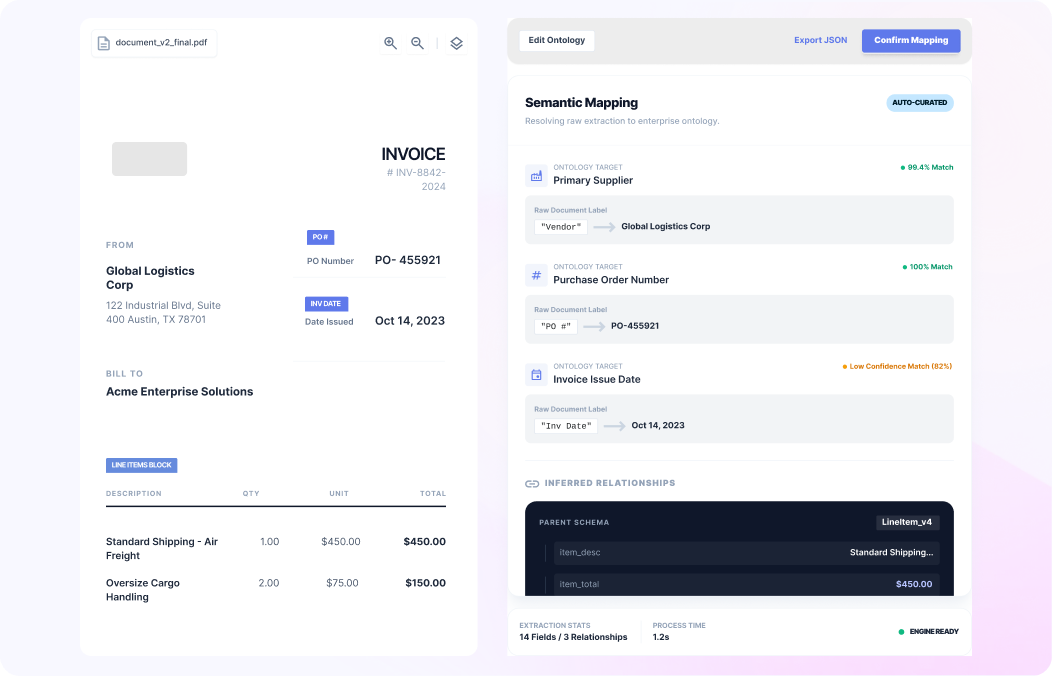
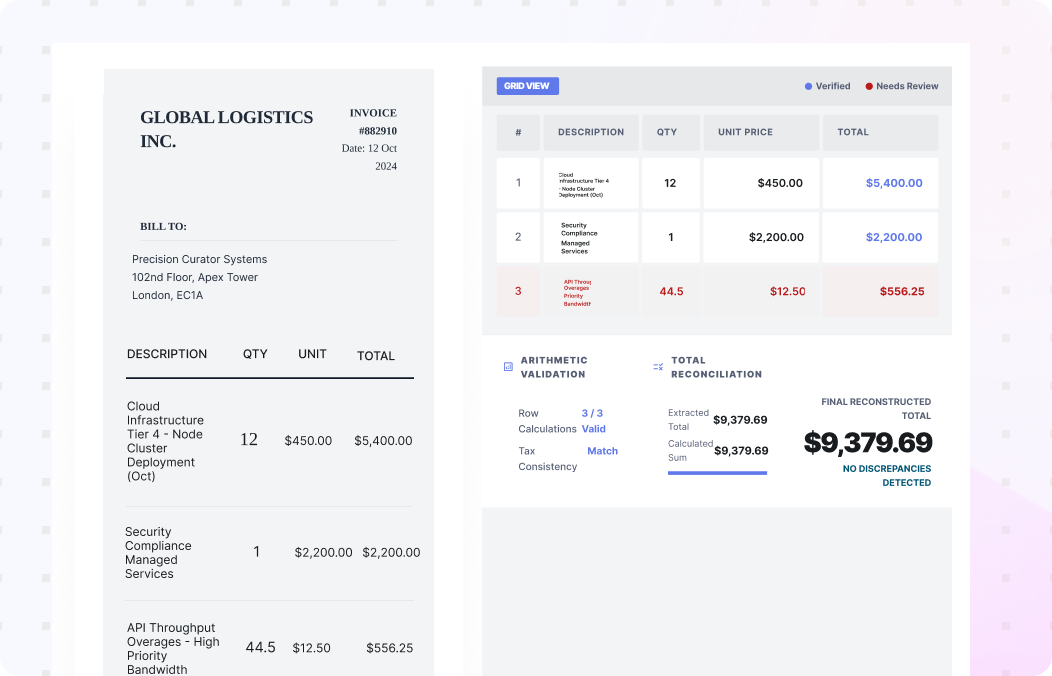
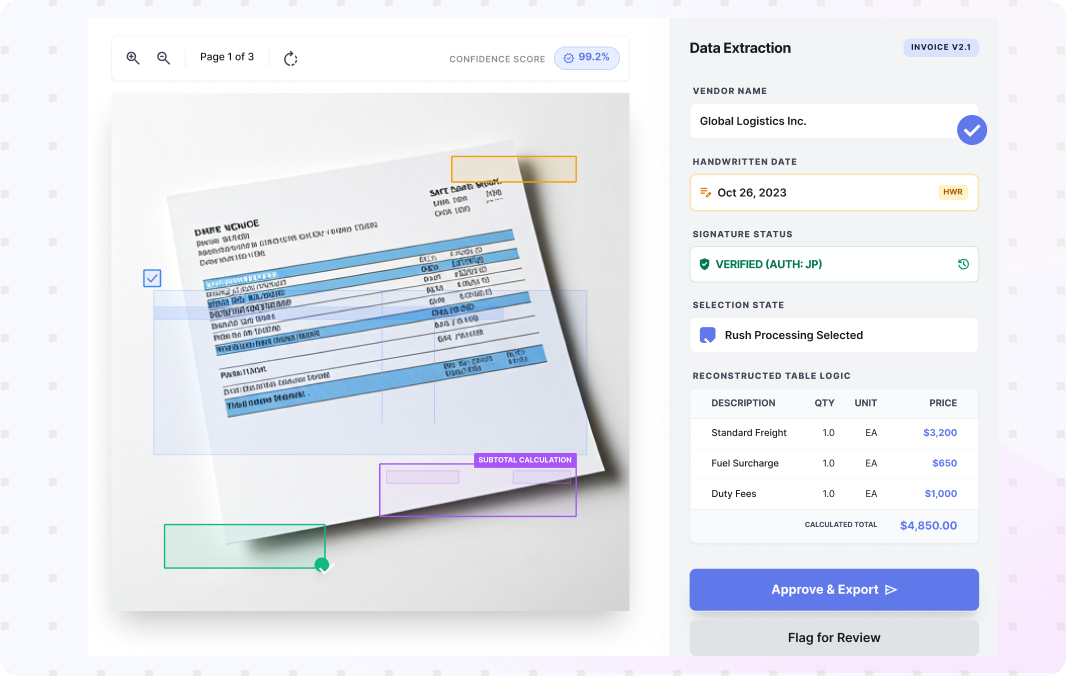
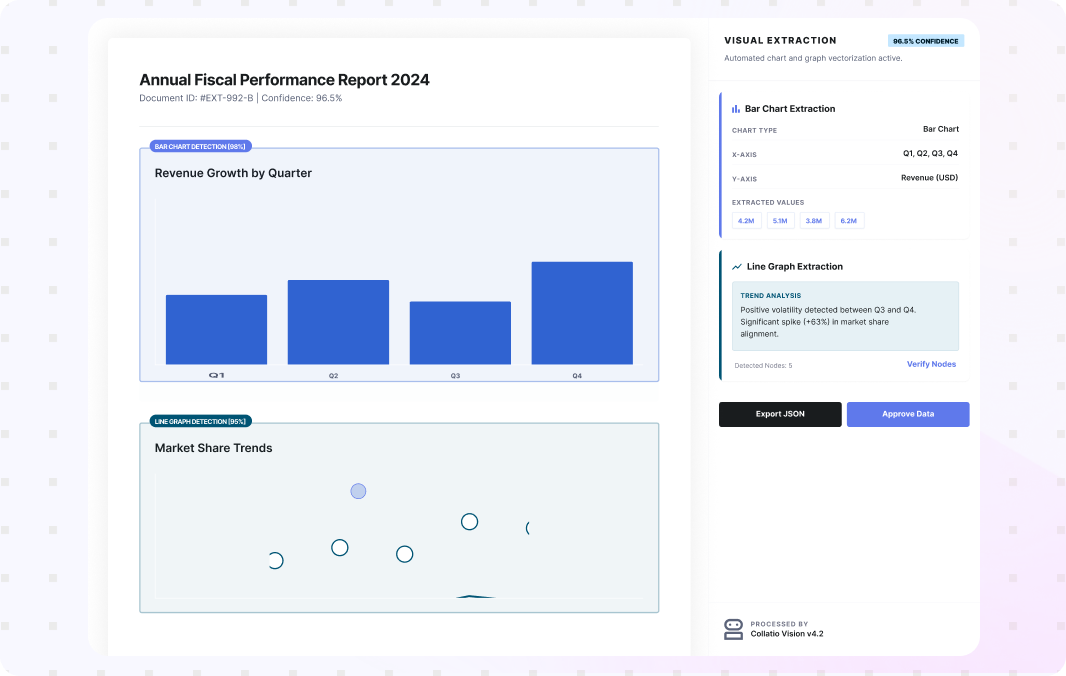
Use AI Document Data Extraction to turn documents into structured fields and tables your teams can use across operations. Collatio extracts values with page-level context, preserves table structure, and supports review for edge cases.
Request a Demo