 Enterprise Knowledge
Agent
Enterprise Knowledge
Agent Realtime Intelligence
Realtime Intelligence Customer Support 360
Customer Support 360 Analytica
Analytica CreditIQ
CreditIQ City Intelligence
City Intelligence Smart Utilities
Smart Utilities Connected Worker & Assets
Connected Worker & Assets Drone Based Infra Monitoring
Drone Based Infra Monitoring SceneTrack
SceneTrack










Dr. Alok Aggarwal
 Accounts Reconciliation
Accounts Reconciliation
 Financial Spreading
Financial Spreading
 Digital Archive
Digital Archive
 SchematicIQ
SchematicIQ
 Loan Ops
Loan Ops
 KYC
KYC
 Docutwin
Docutwin













Automate your workflow with Scry AI Solutions
Get in TouchAs mentioned in a previous article [56], the 1950-82 era saw a new field of Artificial Intelligence (AI) being born,
lot of pioneering research being done, massive hype being created but eventually fizzling out. The 1983-2004
era saw research and development in AI gradually picking up and leading to a few key accomplishments (e.g.,
Deep Blue beating Kasparov in Chess) and commercialized solutions (e.g., Cyberknife), but its pace really
picked up during 2005 and 2010 [57].
Since 2011, AI research and development has been witnessing hypergrowth, and researchers have created
several AI solutions that are almost as good as – or better than – humans in several domains; these include
playing games, healthcare, computer vision and object recognition, speech to text conversion, speaker
recognition, and improved robots and chat-bots for solving specific problems. The table in the Appendix lists
key AI solutions that are rivaling humans in various domains and six of these solutions are described below.
After discussing these six AI solutions, we discuss key reasons for this hypergrowth including the effects of
Moore’s law, parallel and distributed computing, open source software, availability of Big Data, growing
collaboration between academia and industry, and the amount of research that is being done in AI and its
subfields.

In 2006, IBM Watson Research Center embarked on creating IBM Watson, a system that would use machine
learning, natural language processing and information retrieval techniques to beat humans in the game called
Jeopardy!. IBM Watson had 90 servers, each of which used an eight-core processor, four threads per core (i.e.,
total of 2,880 processor threads) and 16 terabytes of RAM [101]. This processing power allowed IBM Watson to
process 500 gigabytes, or about a million books, per second [102]. Today, such a system would cost around
600,000 US Dollars.
IBM researchers realized early on that out of 3,500 randomly selected Jeopardy questions, Wikipedia titles
contained at least 95% of the answers. Hence, IBM Watson contained all of Wikipedia and this “feature
engineering” was one of the key insights for it to win Jeopardy! It also contained 200 million pages of other
content including Wiktionary, Wikiquote, multiple editions of the Bible, encyclopedias, dictionaries, thesauri,
newswire articles, and other literary works, and it used various other databases, taxonomies, and ontologies
(e.g., DBPedia, WordNet, and Yago) to connect various documents [103].

IBM Watson had an ensemble of around 100 algorithms many of which were supervised learning. Although
researchers tried using deep neural networks, logistic regression and related techniques performed much
better. This is not surprising since deep learning networks require massive amounts of data whereas it was
trained only on around 25,000 questions, many of which were taken from old Jeopardy shows. Former
Jeopardy contestants and others also trained IBM Watson, and it played around 100 “rehearsal” matches
where it was correct 71% of the time and won 65% such matches [104].
In 2016, researchers at Google’s DeepMind created AlphaGo that defeated the reigning world champion, Lee
Sodol, in the game of Go. AlphaGo evaluated positions and selected moves using deep neural networks, which
were trained by supervised learning using human expert moves, and by reinforcement learning from self-play.
In 2017, Deep Mind researchers introduced AlphaGo Zero, which was solely based on reinforcement learning,
without human data, guidance or domain knowledge, except for incorporating the rules of the game [94,105].
By playing 4.9 million games against itself, AlphaGo Zero improved and eventually won 100–0 against the
previous champion, AlphaGo.
In 1980s, researchers at Carnegie Mellon University built the first autonomous car prototype but it had limited
capabilities [106]. In 2005, the U.S. Government (via DARPA) launched the “Urban Challenge” for autonomous
cars to obey traffic rules and operate in an urban environment, and in 2009, researchers at Google built such a
self-driving car. In 2015, Nevada, Florida, California, Virginia, Michigan and Washington, D.C. allowed the testing
of autonomous cars on public roads [107], and in 2017, Waymo (a Google’s sister company) announced that it
had begun testing driverless cars without any person in the driver’s position (but still somewhere inside the
car) [108]. Most autonomous car driving software is based on supervised learning and reinforcement learning
techniques as well as computer vision and image processing.
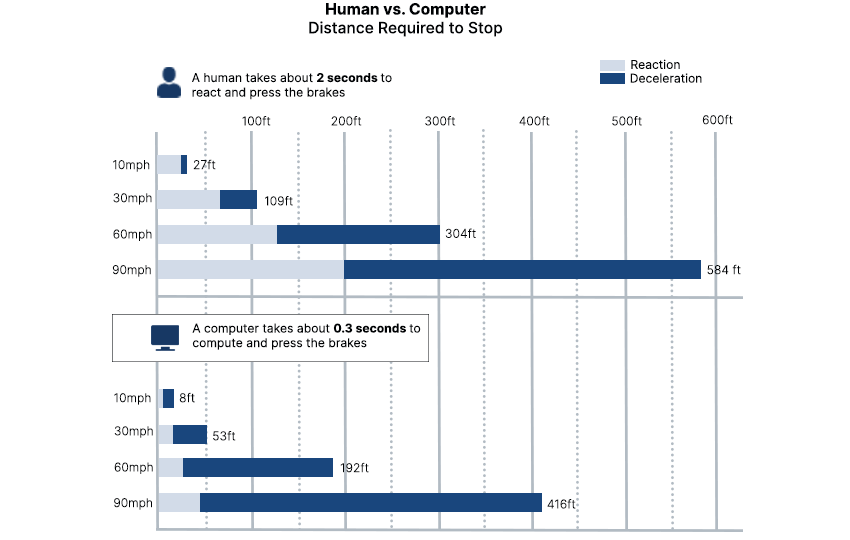
In 2015, a research group led Joel Dudley at Mount Sinai Hospital in New York created a three-layer
unsupervised deep learning network called Deep Patient. Researchers provided Deep Patient data worth
several hundred variables (e.g., medical history, test results, doctor visits, drugs prescribed) for about 700,000
patients [109]. The system was unsupervised and, yet it was able to discover patterns in the hospital data that
indicated as to who was likely to get liver cancer soon. A more interesting aspect was that it could largely
anticipate the onset of psychiatric disorders like schizophrenia. Since schizophrenia is notoriously difficult to
predict even for psychiatrists, Dudley sadly remarked, “We can build these models, but we don’t know how
they work.“
Commercial chatbots started with Siri, which was developed SRI’s Artificial Intelligence Center [110]. Its speech
recognition engine was later provided by Nuance Communications, and was released as an app in Apple
iPhones in February 2010. Other commercial chatbots that were developed during 2011-17 include Microsoft’s
Cortana, Xbox, Skype’s Translator, Amazon’s Alexa, Google’s Now and Allo, Baidu and iFlyTek voice search, and
Nuance speech-based products [111]. The following three humanoid robots are particularly interesting and
there are several others in production or being sold, e.g., Milo, Ekso GT, Deka, and Moley [112]:

Most of these robots use sophisticated control engineering, computer vision, and deep learning networks
(specifically Long-Short Term Memory) but by and large, chatbot dialog still falls far short of human dialog and
there are no accepted benchmarks for comparing them.
To overcome most of these drawbacks, during the last two years, RPA has been combined with machine
learning and natural language processing systems to build more holistic automation systems.

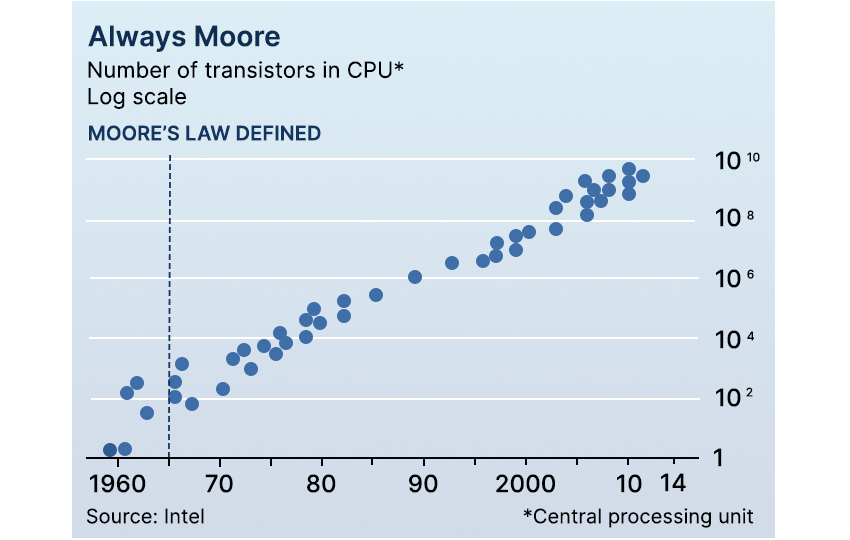
In 1965, Moore observed that the number of transistors in an electronic circuit doubles approximately every
year and he predicted that this rate of growth would continue for a decade [114]. In 1975, he revised his
prediction to doubling every two years [115].

It is important to note that Moore’s law is not really a law, but a set of observations made by Dr. Gordon Moore
who was the founder of Intel Corporation. In fact, in 2015, Moore himself said, “I see Moore’s law dying here in
the next decade or so” [117], which is not surprising since the size of today’s transistors can be reduced by at
most a factor of 4,900 before reaching the theoretical limit of one Silicon atom, which also provides a limitation
on the size and speed of a perceptron. Nevertheless, this exponential increase in computing power, as well as
reduction in size and cost, has had the largest effect on the field of AI.
As mentioned in the previous article [57], most AI algorithms require enormous computing power and by 2004,
parallel and distributed computing became practical. Since electronic communication, storage and computing
have become inexpensive and pervasive, many companies (e.g., Amazon, Microsoft, IBM, Google) are now
selling computation power by the hour or even by the minute, which in turn is helping researchers and
practitioners exploit parallel and distributed computing enormously and executing their algorithms on several
thousand computers simultaneously (by using Hadoop, Spark and related frameworks).
Machine learning algorithms, especially deep learning algorithms, require enormous amount of data. For
example, a supervised neural network with 50 input attributes (or variables) and one output perceptron and
with three hidden layers containing 50 perceptrons each, has 10,050 connections, and this network may
require hundred thousand or more labeled data points for training since each connection’s weight needs to be
optimized. Fortunately, inexpensive and easily available hardware and network connectivity has allowed
humans to produce more than 8 quadrillion Gigabytes (i.e., 8 zetta bytes) of data by 2017 [74]. Many
researchers and developers started using freely available data to create “open” databases for specific
problems and started “crowd sourcing” for labeling this data. MNIST was the first such database created in
1998 and ImageNet has been the largest one that was created in 2011 [72,73]. ImageNet contains more than
14 million URLs of images of which more than 10 million have been hand-labeled to indicate what they
represent.
Open source software allows the freedom for users to execute, modify and redistribute its copies with or
without changes. Richard Stallman, a professor at Carnegie Mellon University, launched the Free Software
Foundation in 1985. In 2002, Torch was the first such machine learning software but since then many others
(e.g., Caffe, Theano, Keras, MXNet, DeepLearning4J, Tensorflow) have been introduced [118,119]. This has
allowed researchers and practitioners to experiment immensely with open source software and build new
algorithms, which if successful, are often made open source too.
According to our estimates, since 1950, more than 200,000 research articles have been written in AI and its
subfields. Out of these, more than 125,000 have been published during 2008-2017 alone. Similarly, there has
been a tremendous growth in industry-academia collaboration since 2008, which is leading to hyper-growth in
building new AI solutions.
“History doesn’t repeat itself but if often rhymes,” is a quote attributed to Mark Twain and it seems to be true
in AI with the enormous excitement that occurred in 1950s and again during the last seven years. In both
cases, researchers got extremely enthusiastic with the hope of quickly creating AI machines that could mimic
humans, and in both cases, this led to hyper-growth in AI research and development.
During 1950s and 1960s, seminal research was done in AI and many of its subfields born, whereas, in the
current phase, powerful and tedious engineering as well as inexpensive and abundant computing led to more
than 20 AI systems that are rivaling or beating humans. And just like the 1950s and 1960s, this has again
created euphoria among researchers, developers, practitioners, investors and the public, which in turn has
started a new hype cycle. We will discuss the characteristics of this hype cycle in the next article, “The Current
Hype Cycle in Artificial Intelligence” [142].
Blog Written by
CEO, Chief Data Scientist at Scry AI
Author of the book The Fourth Industrial Revolution
and 100 Years of AI (1950-2050)


