 Enterprise Knowledge
Agent
Enterprise Knowledge
Agent Realtime Intelligence
Realtime Intelligence Customer Support 360
Customer Support 360 Analytica
Analytica CreditIQ
CreditIQ City Intelligence
City Intelligence Smart Utilities
Smart Utilities Connected Worker & Assets
Connected Worker & Assets Drone Based Infra Monitoring
Drone Based Infra Monitoring SceneTrack
SceneTrack



















Dr. Alok Aggarwal
 Accounts Reconciliation
Accounts Reconciliation
 Financial Spreading
Financial Spreading
 Digital Archive
Digital Archive
 SchematicIQ
SchematicIQ
 Loan Ops
Loan Ops
 Docutwin
Docutwin
 Contract intelligence
Contract intelligence
 KYC/KYB
KYC/KYB
 Form Processing
Form Processing
 Investment Statements
Investment Statements






Ready to Bring AI Automation to Your Business?
Let's DiscussAlthough a few companies began providing high-end, knowledge-based services from India in 1997, this
trend did not gain momentum until six years later. In September 2003, Evalueserve first coined the term
Knowledge Process Outsourcing (KPO), and in January 2004, I gave a talk at Telcordia Laboratories in
New Jersey that “defined” this industry and provided its growth estimates until 2011. Eventually, the
contents of this talk were summarized in an Evalueserve article titled “The Next Big Opportunity –
Moving Up the Value Chain – From BPO to KPO” that was published on July 13, 2004 [1, 2].
Whereas the processes outsourced (e.g., payroll processing, call center work, and accounting) as a part of
Business Process Outsourcing (BPO) require little domain knowledge, require very few “judgment calls”,
and can be usually executed by someone with a high-school diploma, KPO related work requires deeper
domain knowledge and making “judgment calls” in order to achieve better outcomes. Hence, most
professionals involved in KPO have a post-graduate degree (e.g., MBA, Masters in Law, Masters in Engineering or Computer Science, and Masters or PhD in Pharmaceuticals) and the more work- experience they have in their domain, the better results they can produce. Finally, since the work in KPO is domain related, typically a professional working in one of its sub-domain (e.g., intellectual property) will not be able to work effectively in another domain (e.g., doing research related to gas production).
Since the publishing of the first article on KPO in July 2004 [1], the acronym KPO has become part of the
lexicon of the outsourcing industry worldwide. In addition to the nine articles written by Evalueserve on
this topic, more than two hundred independent articles have been written by others (such as Deloitte
Consulting, TPI, NASSCOM and PwC). Furthermore, there are at least six firms that have KPO as part of
their name; several conferences are held every year on KPO; more than 103 captive units of large
multinational companies are providing KPO services from India to their offices in other countries;
majority of midsized and large IT (Information Technology) and BPO (Business Process Outsourcing)
firms in India have a KPO division; and there are at least 182 “niche” companies in India that provide
third-party KPO services.
Historically, our estimates showed that in 2001, the entire KPO industry in India had only 9,000
professionals who generated approximately USD 260 million in revenue; however, this industry had
already grown to approximately 75,000 professionals by 2007. The Indian KPO sector barely grew
during the great recession of 2008-09 but it is likely to have 166,000 professionals by the end of 2014
who will generate annual revenue of approximately USD 6.21 billion. So, overall, during 2001-2014,
this sector has grown approximately 24 times, i.e., at a compound annual growth rate (CAGR) of 27% – 28%. Finally, during the past 13 years, India has generated approximately 70% of the revenue of the global KPO industry and our models show that India’s preeminence in this field will continue until 2020, and perhaps beyond. Hence, India will continue to be the “king,” nay, the “Emperor” in this area.
Within the KPO industry, some sub-sectors such as investment research and business research
outsourcing services grew very quickly during 2001 and 2007, whereas, others like legal process
outsourcing services grew fairly rapidly during 2006 and 2013 [3]. Various sub-sectors of KPO that were
included in the 2004 article [1] and our current forecasts regarding their growth are given in Figure 1.
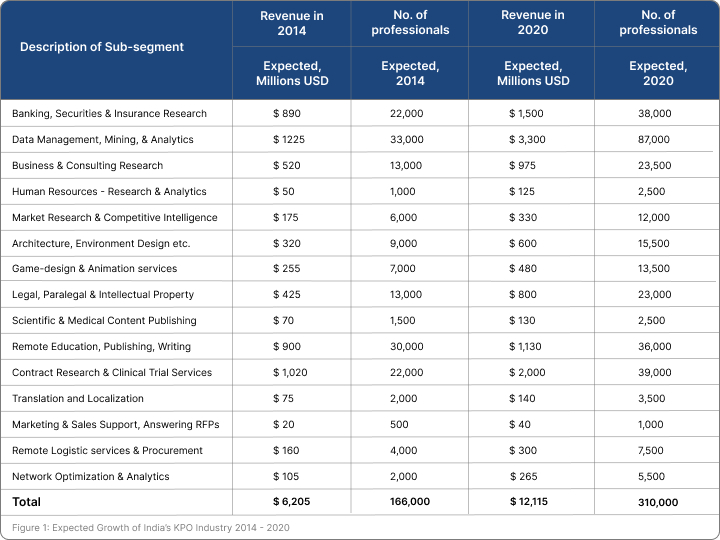
Going forward, our estimates show that overall the KPO outsourcing industry in India is expected to
grow from 166,000 professionals and USD 6.21 billion in revenue in 2014 to 310,000 professionals and
USD 12.12 billion in 2020, which would imply 12% CAGR approximately for the next six years. The
only exception is the sector related to data management, data mining, and analytics, which is expected
to grow from 33,000 professionals and USD 1.23 billion in revenue in 2014 to 87,000 professionals and
USD 3.3 billion in revenue in 2020, thereby implying 18% CAGR. Although an annual growth rate of
18% for the next six years is nothing to sneeze, it is a far cry from the hype that has been created about
such data analytics outsourcing services from India. In the remaining article, we discuss the hype,
myths, and reality related to outsourcing of these data-management related services.
This article is partitioned in five sections. In section 2, we describe the data-information-knowledge
pyramid and the work-flow that is needed to solve various business problems related to analytics. Section 2 also discusses missing gaps in this value chain when it comes to Indian companies. In section 3, we
discuss seven myths related to this sector; for example, we point out that India does not have experienced
analytics professionals that can help in reducing the shortage of experienced analytics professionals in the
United States. Section 4 discusses the potential negative impact of the immigration bill that is pending in
the United States as well as the U.S. government investigations with respect to Infosys and Mu Sigma
regarding potential visa fraud. Finally, Section 5 concludes by stating that since the hype and myths
related to the data analytics outsourcing sector have little connection to reality, these may lead this sector
from boom to bust!
During the last few years, Data Management and Analytics as well as Big Data Science have been often
used interchangeably. Hence, for the sake of completeness, we first define the terms, Big Data and Big
Data Science, and then discuss the workflow and value-chain related to these areas.
The phrase “Big Data” was first coined in 2001 by Doug Laney, a research analyst at Meta Group (now a
part of Gartner) to describe the growth and challenges that are related to data as being three-dimensional,
viz., increasing volume (i.e., amount of data), velocity (i.e., speed of data coming in and going out), and
variety (i.e., range of data types and sources) [4]. In 2012, Laney updated his definition as follows: “Big
data is high volume, high velocity, and/or high variety information assets that require new forms of
processing to enable enhanced decision making, insight discovery and process optimization” [5]. Hence,
unlike traditional analytics, Big Data includes both structured and unstructured data that may be stored in
relational and non-relational databases. Since traditional analytics and business intelligence areas only
handle structured data, Big Data Science is clearly a superset of these areas. In this article, we include all
kinds of data and databases that are related to Big Data Science, which requires the following:
Five key phases in the workflow in Big Data Science for solving a business problem are given below and
can be well understood by using the classical data-information-knowledge pyramid given in Figure 2 [6].
2.1. Data Transformation and Management: Given a specific business problem that needs to be solved, the first and foremost task is to have “good” data that can be used for its analysis. Traditional Extract- Transform-Load (ETL) based approaches push structured data from transactional Enterprise Resource
Planning, Customer Relationship Management and other systems into data warehouses and almost all the
work performed in this regard requires no domain knowledge. Our estimates show that out of 33,000
professionals employed in the data management and analytics outsourcing industry in India today,
approximately 18,000 professionals are employed in the ETL and SQL querying areas who are adept at
handling structured data and doing lower end cleansing work; furthermore, for doing such work, Indian
firms charge between $50,000 and $60,000 per professional per year. However, going forward, given the
characteristics of “Big Data” and the “3Vs” related to it, i.e., volume, velocity, and variety (particularly
with respect to variety related to structured, semi-structured, and unstructured data), our estimates show
that at least two-thirds of all the work in the five phases of this workflow will be actually spent in Big
Data cleansing, munging, wrangling, and harmonizing, which in turn, will depend largely on the domain knowledge of the professionals doing this work. Since most outsourcing companies from India still use
old ETL approaches for data cleansing and do not have domain experts, they run the risk of becoming less
relevant. Furthermore, since these professionals do not have much experience in working with – or in
writing algorithms to cleanse and harmonize – unstructured data, they cannot be used for such intense
data work that is specific to a given domain or a sector.
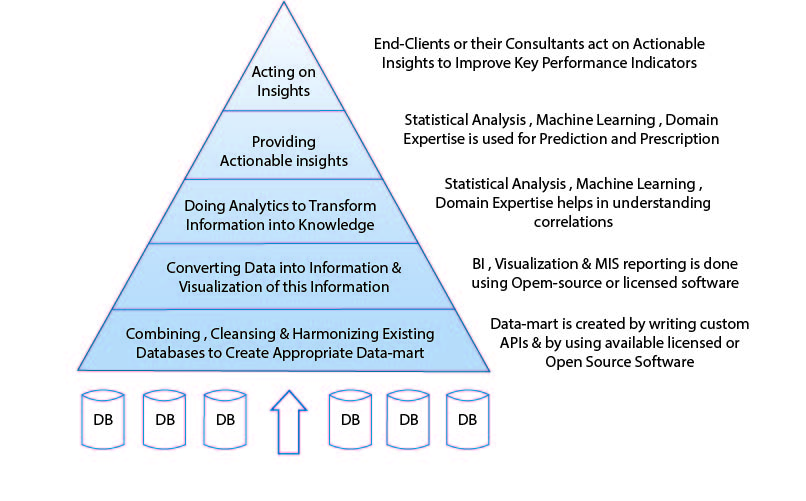
2.2. Descriptive Analytics and Business Intelligence for Converting Data to Information: For a given
business problem, once all of the data has been cleansed, harmonized, and stored in an appropriate
database, descriptive analytics can be done so as to derive and display relevant information. Indeed, by
choosing one of the more than fifty business intelligence software tools, an analyst can display historical
information (e.g., how sales revenue is going up or down for a sales team). Our estimates show that out of
33,000 professionals in this industry in India, approximately 10,000 are employed in business intelligence
(BI) and visualization areas and these professionals typically use Pentaho, Cognos, Business Objects,
Tableau, Qlikview, or home grown solutions that are usually based on Open Source Software. In fact,
more than 80% of the professionals employed by most niche players in India are performing either BI or
ETL activities, and, depending upon their experience, Indian firms charge between $50,000 and $60,000
per professional per year. Again, since these professionals do not have much experience in working with
semi-structured or unstructured data, they cannot be used for displaying such data (e.g., as graphs
containing vertices and edges).
2.3. Predictive Analytics for Providing Knowledge: The next phase in solving a given business problem
is by using predictive analytics, which comprises of statistical and computer science techniques to analyze
cleansed and harmonized data, thereby, gaining knowledge and making predictions about future events.
Our estimates show that out of 33,000 professionals employed in the data management and analytics
industry in India, less than 4,000 are adept at using these techniques, and even in this case, most of them
simply use commercially available software packages (e.g., SAS or SPSS); such professionals are
typically charged at $55,000 to $65,000 per person per year. On the other hand, the Big Data Science
sector is rapidly being transformed by using “R”, Python, and Machine Learning, and therein lays a great chasm that Indian companies need to bridge. Furthermore, for gaining knowledge and making predictions,
Big Data Scientists need to have deep domain knowledge and contextual background of the business
problem being solved, which is by and large non-existent in India.
2.4. Generating Actionable Insights: The fourth phase includes prescriptive analytics and generating actionable insights, thereby, providing decision support. If the data scientists working on a given business problem understand the domain well, they can build and run their analytic algorithms for alternate scenarios in order to improve key performance indicators related to a business problem. Of course,
depending on the domain and the business problem, such key indicators may include increasing revenue
or reducing cost, ensuring compliance, reducing risk, and improving timeliness, quality, and customer
experience. However, given that the Indian analytics industry is quite nascent and there is massive job-
hopping in this industry (Cf. Section 4), out of 33,000 professionals today, there are less than 1,000 data
scientists who have the required math, statistics, and computer science backgrounds and the required
domain expertise to generate such insights. Most such data scientists exist in niche’ firms who have less
than 100 employees that charge $120,000 to $150,000 for each such data scientist per year.
2.5. Acting on the Actionable Insights: The fifth and final phase in this workflow involves acting upon
the actionable insights that were generated in the previous phase. Clearly, this task cannot be done from
India and has to be done onsite either by the end-client or by external consultants used by the client.
During this phase, issues related to correlation versus causation become extremely important and hence
having the required domain knowledge becomes even more critical to the overall success of the project.
Of course, once clients have acted upon these insights, they may embark on one or more business
problems in the same or different areas or they may decide to analyze the same problem on a periodic
basis by using additional internal or external data, in which case, the entire work-flow would be repeated.
A 2011 report from McKinsey Global Institute [7] states that by 2018 in the United States, “demand for
deep analytical positions in big data world could exceed the supply …. by 140,000 to 190,000 positions.
Furthermore, this type of talent is difficult to produce, taking years of training with someone with
intrinsic mathematical abilities…. In addition, we project a need for 1.5 million additional managers and
analysts in the United States who can ask the right questions and consume the results of the analysis of
big data effectively. The United States …. cannot fill this gap by simply changing the graduate
requirements and waiting for people to graduate with more skills or by importing talent…”
In India, since most professionals who have a math, engineering or computer science background end up
joining IT services firm, and since for the next six years, these firms will require approximately 1.2
million new employees, our estimates show that it would be hard for data analytics related areas to attract
and retain more than 54,000 new employees. Hence, the data management and analytics outsourcing
industry in India will be more constrained by the supply of experienced professionals than by the demand
that may exist around the world. Given this backdrop, following are seven myths related to outsourcing of
data analytics services from India:
Myth 1; Shortage of Data Scientists in the U.S can be fulfilled by those in India: According to
Robert Charrete [8], the United States actually produces more than 440,000 graduates and post-graduates
every year in STEM (Science, Technology, Engineering, and Math) areas, and according to the U.S.
Commerce Department, there are 7.6 million professionals working in these areas [8]. However, as per
the McKinsey Global Institute, most of these professionals do not have the experience or expertise to be
Data Scientists and it takes several years to develop these intrinsic capabilities [7]. If the United States is
going to have a shortage of Data Scientists because its professionals either do not have the appropriate
math/computer science skills or the appropriate domain expertise then this problem will be even more
exacerbated in India. Furthermore, since Indian domestic firms are still not using analytics for their own businesses, it is very hard for Indian professionals to leapfrog and acquire the domain expertise regarding
such business problems.
Myth 2; Graduates in India can be converted into Data Scientists by providing 3-6 months of
training: Many firms in India, especially those that are “pure play” firms, have started training their
employees by providing them a three to six months course related to analytics and Big Data Science.
Although such training is laudable and will certainly help in developing this nascent area, it is a far cry
from calling such professionals Big Data Scientists or even experienced analysts. In fact, it is far worse
when these niche firms hype up their training departments and call them “Universities.” Not only is this a
travesty of the Indian education system, it is patently illegal since accreditation from an appropriate
government body is compulsory for all universities except those created by the Indian Parliament [9].
Myth 3; Data Management and Analytics Professionals from India can be charged at almost
the same rates as those in the U.S: Most analytics professionals in India lack mature domain expertise
and they have little experience in high-end statistical techniques (e.g., Bayesian), in artificial intelligence
algorithms or in Python language. Hence, at least for the near future, such professionals will be only
relegated to doing lower end work, thereby, earning the same kinds of salaries as those in other areas of
KPO. Keeping this in view, the end-clients in the U.S. and other developed countries will have to do
substantial due-diligence to see whether an Indian firm has the required domain expertise or if it can only
perform lower end work. And, the best hope for the Indian outsourcing industry is that the managers at
the clients’ end in the U.S. or Europe partition their business problems into sub-problems and the give
these sub-problems to professionals in India, thereby, saving 70% in costs for solving these sub-problems.
Myth 4; Attrition within the Analytics Outsourcing Industry in India is low: Like other sub-
sectors of KPO, attrition in data analytics is approximately 30%, which implies that most data analytics
firms have become “hiring and training machines.” Reasons for higher attrition include late-night working
schedule (which destroys analysts’ work-life balance), boredom with low-end work, and the continued
shortage of such professionals in India. Shortage of such professionals also implies a continued pressure
on wages, thereby, ensuring job-hopping by professionals for a mere wage increase of 15%-20%.
Unfortunately, this shortage will continue for at least the next six years because less than ten universities
and colleges in India are currently offering – or thinking of offering – degrees in this area, which in turn,
is due to an acute shortage of professors in this area. Unfortunately, attrition and “job hopping” further
reduces the acquisition of domain expertise because whenever professionals leave a firm to join another,
they end up learning very little during the last two months of the firm they are leaving and the first two
months of the firm that they are joining.
Myth 5; This time it is different with Data Analytics Outsourcing: In fact, exactly the opposite
is true. Most analytics firms in India are currently following the old beaten path of FTE (Full-Time
Equivalent) pricing and providing these professionals in a staff augmentation mode. Furthermore, like
other sectors of KPO, because there are very few barriers to entry and because the capital requirements of
starting a data analytics firm are very low, there are already more than 180 organizations, which are either
pure-play analytics firms or analytics divisions of larger companies (Cf. Appendix). Clearly, small and
nimble players can keep their overheads (e.g., Sales, General and Administration expenses) low, thereby,
undercutting others and ensuring a race to the bottom with respect to both prices and profit margins.
Hence, just like the other sub-sectors of KPO and ITO, firms in the data analytics sector are already
beginning to witness an LTM-EBITDA (Earnings Before Interest, Taxes, Depreciation and Amortization
for the Last Twelve Months) of 20%-22% with respect to the last twelve months’ (LTM) revenue and this
trend will become even more pronounced in the future.
Myth 6; By creating a few APIs or home-grown visualization software, a Data Analytics
Services company can stand out: In order to differentiate themselves from the pack of the 180 or more analytics companies and divisions in India, several niche companies have started creating “software
macros” or home-grown visualization software. Overall, this seems to be a great move but because there
are already more than 50 visualization software companies in the world, it is not clear that building home-
grown visualization software would help them unless their software is really intuitive and captivating with
a broad appeal. In our view, if the Indian firms really want to differentiate themselves, they would need to
spend significantly more time in developing domain expertise among their professionals or “pivot” their
firms to creating end-to-end solutions.
Myth 7; Valuations for Analytics Outsourcing Companies will be significantly higher than
other KPO companies: Since analytics firms in India are doing low-end analytics work and lack mature
domain expertise, comparison of such companies to Splunk or Palantir seems far-fetched; indeed, Palantir
has deep domain expertise in defense, law enforcement, banking and insurance sectors, whereas, Splunk
has deep expertise in “machine data” that is being generated by “Internet of Things”. Also, according to
our estimates, most KPO companies in India are likely to grow at approximately 12% CAGR for the next
six years and their current valuation would be around 11 to 12 times LTM-EBITDA. Hence, it is hard to
see how the corresponding valuation for the corresponding data analytics services firms in India would be
more than 16-18 times LTM-EBITDA, especially when they are likely to grow at 18% CAGR (for the
next six years).
The Immigration Reform Bill that is pending in the United States and that may be taken up sometime in
2015 has the following clauses, which may have a more pronounced effect for data analytics outsourcing
firms than those providing IT outsourcing, BPO and other KPO services:
Since Data Analytics and Big Data Science area requires most managers and analysts to be onsite (for
understanding the business problem and working with associated data), the above mentioned pending
immigration bill and the following investigations by the U.S. Government with respect to Infosys and Mu
Sigma for visa fraud may cast a dark shadow on this area.
In 2011, the United States Government accused Infosys of using workers with a B-1 visa (which only
allows temporary entry for business purposes) to perform skilled labor jobs in the United States. The U.S.
Government said that these jobs should have been performed by workers with H1-B or L-1 visas only, the
appropriate visas for foreign nationals to enter the U.S. to perform such skilled jobs. In October 2013,
Infosys eventually entered into a settlement with the U.S. Government to settle allegations of systemic
fraud and abuse of immigration processes and agreed to pay USD 34 million as a penalty [11, 12].
Similarly, in 2014, Mu Sigma confirmed that the U.S. Government is investigating allegations whether
Mu Sigma has engaged in visa fraud. The investigation into Mu Sigma is reminiscent of the one filed
against Infosys mentioned above, and it is not clear as to how this case will turn out [13, 14].
Clearly, the future of the data analytics outsourcing industry in India is bright; however, as discussed
above, the hype and myths around this industry seem to have little – or no connection – to reality, which
may lead this industry from a boom to a bust! Unfortunately, if this industry goes bust then not only will
all data analytics outsourcing firms and their employees suffer, it will also preclude India from becoming
a “Giant” and gain a near “Emperor” status in this area as it has become in the Information Technology
field. According to a recent study by IDC [15], there were 29 million workers in the ICT (Information and
Communication Technology) areas in 2013 out of which 10.4% were present in India, making it the
second largest reservoir of such professionals after the United States of America that has 22% of all such
workers. Such a prowess not only helps India in its domestic and exports IT industry but also helps in
other industries. For example, most experts believe that the reason why Indian scientists were successful
in their first mission of sending a spaceship, Mangalyaan, to Mars for a meagre expense of USD 74
million (whereas Japan and China failed) was mainly due to their IT expertise and the ability to simulate
many required processes on a computer [16].
Blog Written by
CEO, Chief Data Scientist at Scry AI
Author of the book The Fourth Industrial Revolution
and 100 Years of AI (1950-2050)


