
Dr. Alok Aggarwal
Ready to Bring AI Automation to Your Business?
Let's DiscussWhile artificial intelligence (AI) is among today’s most popular topics, a commonly forgotten fact is that it was actually born in 1950 and went through a hype cycle between 1956 and 1982. The purpose of this article is to
highlight some of the achievements that took place during the boom phase of this cycle and explain what led
to its bust phase. The lessons to be learned from this hype cycle should not be overlooked – its successes
formed the archetypes for machine learning algorithms used today, and its shortcomings indicated the
dangers of overenthusiasm in promising fields of research and development.
Although the first computers were developed during World War II [1,2], what seemed to truly spark the field of
AI was a question proposed by Alan Turing in 1950 [3]: can a machine imitate human intelligence? In his
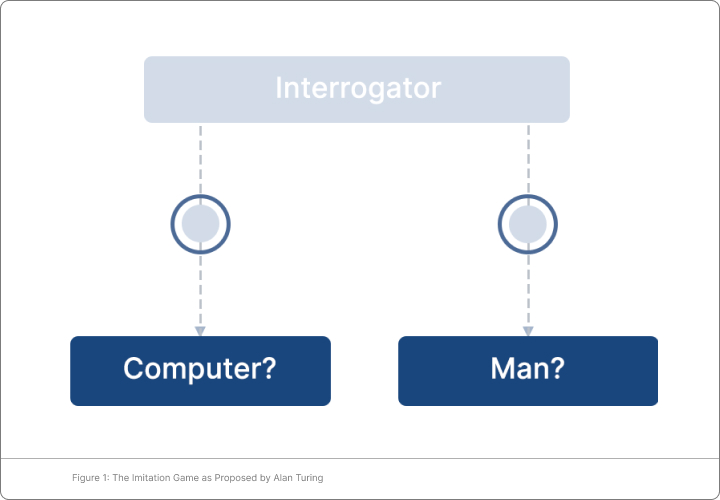
seminal paper, “Computing Machinery and Intelligence,” he formulated a game, called the imitation game, in
which a human, a computer, and a (human) interrogator are in three different rooms. The interrogator’s goal is
to distinguish the human from the computer by asking them a series of questions and reading their
typewritten responses; the computer’s goal is to convince the interrogator that it is the human [3]. In a 1952
BBC interview, Turing suggested that, by the year 2000, the average interrogator would have less than a 70%
chance of correctly identifying the human after a five-minute session [4].
Turing was not the only one to ask whether a machine could model intelligent life. In 1951, Marvin Minsky, a
graduate student inspired by earlier neuroscience research indicating that the brain was composed of an
electrical network of neurons firing with all-or-nothing pulses, attempted to computationally model the
behavior of a rat. In collaboration with physics graduate student Dean Edmonds, he built the first neural
network machine called Stochastic Neural Analogy Reinforcement Computer (SNARC) [5]. Although primitive
(consisting of about 300 vacuum tubes and motors), it was successful in modeling the behavior of a rat in a
small maze searching for food [5].
The notion that it might be possible to create an intelligent machine was an alluring one indeed, and it led to several subsequent developments. For instance, Arthur Samuel built a Checkers-playing program in 1952 that
was the world’s first self-learning program [12]. Later, in 1955, Newell, Simon and Shaw built Logic Theorist,
which was the first program to mimic the problem-solving skills of a human and would eventually prove 38 of
the first 52 theorems in Whitehead and Russell’s Principia Mathematica [6].

Inspired by these successes, young Dartmouth professor John McCarthy organized a conference in 1956 to
gather twenty pioneering researchers and, “explore ways to make a machine that could reason like a human,
was capable of abstract thought, problem-solving and self-improvement” [7]. It was in his 1955 proposal for
this conference where the term, “artificial intelligence,” was coined [7,40,41,42], and it was at this conference
where AI gained its vision, mission, and hype.
Researchers soon began making audacious claims about the incipience of powerful machine intelligence, and
many anticipated that a machine as intelligent as a human would exist in no more than a generation [40, 41,
42]. For instance:

AI had even caught Hollywood’s attention. In 1968, Arthur Clarke and Stanley Kubrick produced the movie,
2001: A Space Odyssey, whose antagonist was an artificially intelligent computer, HAL 9000 exhibiting
creativity, a sense of humor, and the ability to scheme against anyone who threatened its survival. This was
based on the belief held by Turing, Minsky, McCarthy and many others that such a machine would exist by
2000; in fact, Minsky served as an adviser for this film and one of its characters, Victor Kaminski, was named in
his honor.

Between 1956 and 1982, the unabated enthusiasm in AI led to seminal work, which gave birth to several
subfields of AI that are explained below. Much of this work led to the first prototypes for the modern theory of
AI.
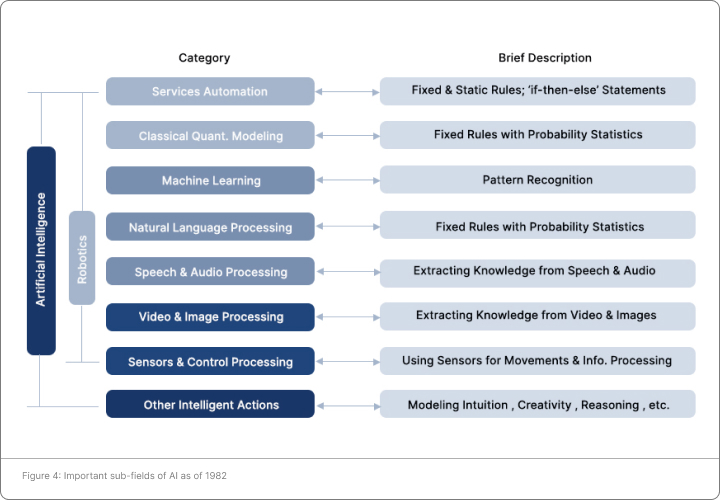
Rule based expert systems try to solve complex problems by implementing series of “if-then-else” rules. One
advantage to such systems is that their instructions (what the program should do when it sees “if” or “else”)
are flexible and can be modified either by the coder, user or program itself. Such expert systems were created
and used in the 1970s by Feigenbaum and his colleagues [13], and many of them constitute the foundation
blocks for AI systems today.
The field of machine learning was coined by Arthur Samuel in 1959 as, “the field of study that gives computers
the ability to learn without being explicitly programmed” [14]. Machine learning is a vast field and its detailed
explanation is beyond the scope of this article. The second article in this series – see Prologue on the first page and [57] – will briefly discuss its subfields and applications. However, below we give one example of a machine learning program, known as the perceptron network.

Single and Multilayer Perceptron Networks
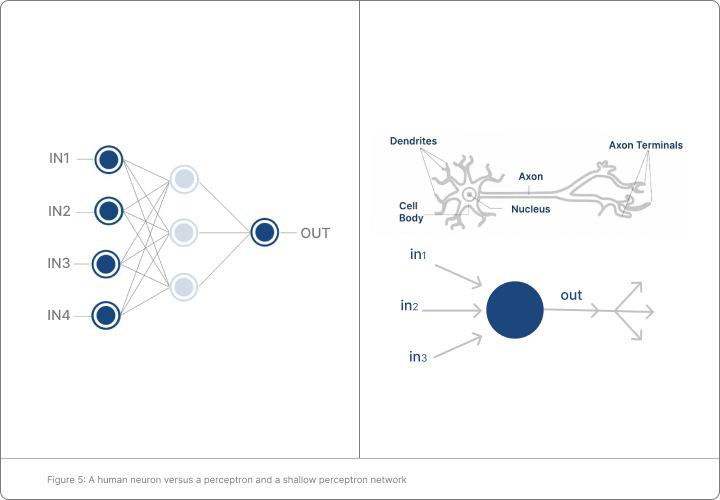
Inspired by the work of McCulloch and Pitts in 1943 and of Hebb in 1949 [15,16], Rosenblatt in 1957 introduced
the perceptron network as an artificial model of communicating neurons [17]. This model is shown in Figure 5
and can be briefly described as follows. One layer of vertices, where input variables are entered, is connected
to a hidden layer of vertices (also called perceptrons), which in turn is connected to an output layer of
perceptrons. A signal coming via a connection from an input vertex to a perceptron in the hidden layer is
calibrated by a “weight” associated with that connection, and this weight is assigned during a “learning
process”. Signals from hidden layer perceptrons to output layer perceptrons are calibrated in an analogous
way. Like a human neuron, a perceptron “fires” if the total weight of all incoming signals exceeds a specified
potential. However, unlike for humans, signals in this model are only transmitted towards the output layer,
which is why these networks are often called “feed-forward.” Perceptron networks with only one hidden layer
of perceptrons (i.e., with two layers of weighted edge connections) later became known as “shallow” artificial
neural networks. Although shallow networks were limited in power, Rosenblatt managed to create a one-layer
perceptron network, which he called created Mark 1, that was able to recognize basic images [17].
Today, the excitement is about “deep” (two or more hidden layers) neural networks, which were also studied in
the 1960s. Indeed, the first general learning algorithm for deep networks goes back to the work of Ivakhnenko
and Lapa in 1965 [18,19]. Networks as deep as eight layers were considered by Ivakhnenko in 1971, when he
also provided a technique for training them [20].
In 1957 Chomsky revolutionized linguistics with universal grammar, a rule based system for understanding
syntax [21]. This formed the first model that researchers could use to create successful NLP systems in the
1960s, including SHRDLU, a program which worked with small vocabularies and was partially able to
understand textual documents in specific domains [22]. During the early 1970s, researchers started writing
conceptual ontologies, which are data structures that allow computers to interpret relationships between
words, phrases and concepts; these ontologies widely remain in use today [23].
The question of whether a computer could recognize speech was first proposed by a group of three
researchers at AT&T Bell Labs in 1952, when they built a system for isolated digit recognition for a single
speaker [24]. This system was vastly improved upon during the late 1960s, when Reddy created the Hearsay I, a program which had low accuracy but was one of the first to convert large vocabulary continuous speech into text. In
1975, his students Baker and Baker created the Dragon System [25], which further improved upon Hearsay I by
using the Hidden Markov Model (HMM), a unified probabilistic model that allowed them to combine various
sources such as acoustics, language, and syntax. Today, the HMM remains an effective framework for speech
recognition [26].
In the summer of 1966, Minsky hired a first-year undergraduate student at MIT and asked him to solve the
following problem: connect a television camera to a computer and get the machine to describe what it sees
[27]. The aim was to extract three-dimensional structure from images, thereby enabling robotic sensory
systems to partially mimic the human visual system. Research in computer vision in the early 1970s formed the
foundation for many algorithms that exist today, including extracting edges from images, labeling lines and
circles, and estimating motion in videos [28].
The above theoretical advances led to several applications, most of which fell short of being used in practice at
that time but set the stage for their derivatives to be used commercially later. Some of these applications are
discussed below.
Between 1964 and 1966, Weizenbaum created the first chat-bot, ELIZA, named after Eliza Doolittle who was
taught to speak properly in Bernard Shaw’s novel, Pygmalion (later adapted into the movie, My Fair Lady).
ELIZA could carry out conversations that would sometimes fool users into believing that they were
communicating with a human but, as it happens, ELIZA only gave standard responses that were often
meaningless [29]. Later in 1972, medical researcher Colby created a “paranoid” chatbot, PARRY, which was also
a mindless program. Still, in short imitation games, psychiatrists were unable to distinguish PARRY’s ramblings
from those of a paranoid human’s [30].

In 1954, Devol built the first programmable robot called, Unimate, which was one of the few AI inventions of its
time to be commercialized; it was bought by General Motors in 1961 for use in automobile assembly lines [31].
Significantly improving on Unimate, in 1972, researchers at Waseda University in 1972 built the world’s first full-
scale intelligent humanoid robot, WABOT-1 [32]. Although it was almost a toy, its limb system allowed it to walk
and grip as well as transport objects with hands; its vision system (consisting of its artificial eyes and ears)
allowed it to measure distances and directions to objects; and its artificial mouth allowed it to converse in
Japanese [32]. This gradually led to innovative work in machine vision, including the creation of robots that
could stack blocks [33].

Despite some successes, by 1975 AI programs were largely limited to solving rudimentary problems. In
hindsight, researchers realized two fundamental issues with their approach.
In 1976, the world’s fastest supercomputer (which would have cost over five million US Dollars) was only
capable of performing about 100 million instructions per second [34]. In contrast, the 1976 study by Moravec
indicated that even the edge-matching and motion detection capabilities alone of a human retina would
require a computer to execute such instructions ten times faster [35]. Likewise, a human has about 86 billion
neurons and one trillion synapses; basic computations using the figures provided in [36,37] indicate that
creating a perceptron network of that size would have cost over 1.6 trillion USD, consuming the entire U.S.
GDP in 1974.
Scientists did not understand how the human brain functions and remained especially unaware of the
neurological mechanisms behind creativity, reasoning and humor. The lack of an understanding as to what
precisely machine learning programs should be trying to imitate posed a significant obstacle to moving the
theory of artificial intelligence forward. In fact, in the 1970s, scientists in other fields even began to question
the notion of, ‘imitating a human brain,’ proposed by AI researchers. For example, some argued that if
symbols have no ‘meaning’ for the machine, then the machine could not be described as ‘thinking’ [38].
Eventually it became obvious to the pioneers that they had grossly underestimated the difficulty of creating an
AI computer capable of winning the imitation game. For example, in 1969, Minsky and Papert published the
book, Perceptrons [39], in which they indicated severe limitations of Rosenblatt’s one-hidden layer perceptron.
Coauthored by one of the founders of artificial intelligence while attesting to the shortcomings of perceptrons,
this book served as a serious deterrent towards research in neural networks for almost a decade [40,41,42].
In the following years, other researchers began to share Minsky’s doubts in the incipient future of strong AI.
For example, in a 1977 conference, a now much more circumspect John McCarthy noted that creating such a
machine would require ‘conceptual breakthroughs,’ because ‘what you want is 1.7 Einsteins and 0.3 of the
Manhattan Project, and you want the Einsteins first. I believe it’ll take five to 500 years’ [43].
The hype of the 1950s had raised expectations to such audacious heights that, when the results did not
materialize by 1973, the U.S. and British governments withdrew research funding in AI [41]. Although the
Japanese government temporarily provided additional funding in 1980, it quickly became disillusioned by the
late 1980s and withdrew its investments again [42, 40,]. This bust phase (particularly between 1974 and 1982)
is commonly referred to as the “AI winter,” as it was when research in artificial intelligence almost stopped
completely. Indeed, during this time and the subsequent years, “some computer scientists and software
engineers would avoid the term artificial intelligence for fear of being viewed as wild-eyed dreamers”
[44].

The prevailing attitude during the 1974-1982 period was highly unfortunate, as the few substantial advances
that took place during this period essentially went unnoticed, and significant effort was undertaken to recreate
them. Two such advances are the following:
The defining characteristics of a hype cycle are a boom phase, when researchers, developers and investors
become overly optimistic and enormous growth takes place, and a bust phase, when investments are
withdrawn, and growth reduces substantially. From the story presented in this article, we can see that AI went
through such a cycle during 1956 and 1982.
Born from the vision of Turing and Minsky that a machine could imitate intelligent life, AI received its name,
mission, and hype from the conference organized by McCarthy at Dartmouth University in 1956. This marked
the beginning of the boom phase of the AI hype cycle. Between 1956 and 1973, many penetrating theoretical
and practical advances were discovered in the field of AI, including rule-based systems; shallow and deep
neural networks; natural language processing; speech processing; and image recognition. The achievements
that took place during this time formed the initial archetypes for current AI systems.
What also took place during this boom phase was “irrational exuberance” [52]. The pioneers of AI were quick
to make exaggerated predictions about the future of strong artificially intelligent machines. By 1974, these
predictions did not come to pass, and researchers realized that their promises had been inflated. By this point,
investors had also become skeptical and withdrew funding. This resulted in a bust phase, also called the AI
winter, when research in AI was slow and even the term, “artificial intelligence,” was spurned. Most of the few
inventions during this period, such as backpropagation and recurrent neural networks, went largely
overlooked, and substantial effort was spent to rediscover them in the subsequent decades.
Most of the few inventions during this period, such as backpropagation and recurrent neural networks, went
largely overlooked, and substantial effort was spent to rediscover them in the subsequent decades.
Nevertheless, like most hype cycles, “green shoots” start appearing again in mid 1980s and there was a
gradual resurgence of AI research during 1983 and 2010; we will discuss these and related developments in
our next article, “Resurgence of Artificial Intelligence During 1983-2010” [57].
In general hype cycles are double-ended swords, and the one exhibited by AI between 1956 and 1982 was no
different. Care must be taken to learn from it: the successes of its boom phase should be remembered and
appreciated, but its overenthusiasm should be viewed with at least some skepticism to avoid the full penalties
of the bust phase.
Blog Written by
CEO, Chief Data Scientist at Scry AI
Author of the book The Fourth Industrial Revolution
and 100 Years of AI (1950-2050)
At Scry Analytics Inc ("us", "we", "our" or the "Company") we value your privacy and the importance of safeguarding your data. This Privacy Policy (the "Policy") describes our privacy practices for the activities set out below. As per your rights, we inform you how we collect, store, access, and otherwise process information relating to individuals. In this Policy, personal data (“Personal Data”) refers to any information that on its own, or in combination with other available information, can identify an individual.
We are committed to protecting your privacy in accordance with the highest level of privacy regulation. As such, we follow the obligations under the below regulations:
This policy applies to the Scry Analytics, Inc. websites, domains, applications, services, and products.
This Policy does not apply to third-party applications, websites, products, services or platforms that may be accessed through (non-) links that we may provide to you. These sites are owned and operated independently from us, and they have their own separate privacy and data collection practices. Any Personal Data that you provide to these websites will be governed by the third-party’s own privacy policy. We cannot accept liability for the actions or policies of these independent sites, and we are not responsible for the content or privacy practices of such sites.
This Policy applies when you interact with us by doing any of the following:
What Personal Data We Collect
When attempt to contact us or make a purchase, we collect the following types of Personal Data:
This includes:
Account Information such as your name, email address, and password
Automated technologies or interactions: As you interact with our website, we may automatically collect the following types of data (all as described above): Device Data about your equipment, Usage Data about your browsing actions and patterns, and Contact Data where tasks carried out via our website remain uncompleted, such as incomplete orders or abandoned baskets. We collect this data by using cookies, server logs and other similar technologies. Please see our Cookie section (below) for further details.
If you provide us, or our service providers, with any Personal Data relating to other individuals, you represent that you have the authority to do so and acknowledge that it will be used in accordance with this Policy. If you believe that your Personal Data has been provided to us improperly, or to otherwise exercise your rights relating to your Personal Data, please contact us by using the information set out in the “Contact us” section below.
When you visit a Scry Analytics, Inc. website, we automatically collect and store information about your visit using browser cookies (files which are sent by us to your computer), or similar technology. You can instruct your browser to refuse all cookies or to indicate when a cookie is being sent. The Help Feature on most browsers will provide information on how to accept cookies, disable cookies or to notify you when receiving a new cookie. If you do not accept cookies, you may not be able to use some features of our Service and we recommend that you leave them turned on.
We also process information when you use our services and products. This information may include:
We may receive your Personal Data from third parties such as companies subscribing to Scry Analytics, Inc. services, partners and other sources. This Personal Data is not collected by us but by a third party and is subject to the relevant third party’s own separate privacy and data collection policies. We do not have any control or input on how your Personal Data is handled by third parties. As always, you have the right to review and rectify this information. If you have any questions you should first contact the relevant third party for further information about your Personal Data.
Our websites and services may contain links to other websites, applications and services maintained by third parties. The information practices of such other services, or of social media networks that host our branded social media pages, are governed by third parties’ privacy statements, which you should review to better understand those third parties’ privacy practices.
We collect and use your Personal Data with your consent to provide, maintain, and develop our products and services and understand how to improve them.
These purposes include:
Where we process your Personal Data to provide a product or service, we do so because it is necessary to perform contractual obligations. All of the above processing is necessary in our legitimate interests to provide products and services and to maintain our relationship with you and to protect our business for example against fraud. Consent will be required to initiate services with you. New consent will be required if any changes are made to the type of data collected. Within our contract, if you fail to provide consent, some services may not be available to you.
Where possible, we store and process data on servers within the general geographical region where you reside (note: this may not be within the country in which you reside). Your Personal Data may also be transferred to, and maintained on, servers residing outside of your state, province, country or other governmental jurisdiction where the data laws may differ from those in your jurisdiction. We will take appropriate steps to ensure that your Personal Data is treated securely and in accordance with this Policy as well as applicable data protection law.Data may be kept in other countries that are considered adequate under your laws.
We will share your Personal Data with third parties only in the ways set out in this Policy or set out at the point when the Personal Data is collected.
We also use Google Analytics to help us understand how our customers use the site. You can read more about how Google uses your Personal Data here: Google Privacy Policy
You can also opt-out of Google Analytics here: https://tools.google.com/dlpage/gaoptout
We may use or disclose your Personal Data in order to comply with a legal obligation, in connection with a request from a public or government authority, or in connection with court or tribunal proceedings, to prevent loss of life or injury, or to protect our rights or property. Where possible and practical to do so, we will tell you in advance of such disclosure.
We may use a third party service provider, independent contractors, agencies, or consultants to deliver and help us improve our products and services. We may share your Personal Data with marketing agencies, database service providers, backup and disaster recovery service providers, email service providers and others but only to maintain and improve our products and services. For further information on the recipients of your Personal Data, please contact us by using the information in the “Contacting us” section below.
A cookie is a small file with information that your browser stores on your device. Information in this file is typically shared with the owner of the site in addition to potential partners and third parties to that business. The collection of this information may be used in the function of the site and/or to improve your experience.
To give you the best experience possible, we use the following types of cookies: Strictly Necessary. As a web application, we require certain necessary cookies to run our service.
We use preference cookies to help us remember the way you like to use our service. Some cookies are used to personalize content and present you with a tailored experience. For example, location could be used to give you services and offers in your area. Analytics. We collect analytics about the types of people who visit our site to improve our service and product.
So long as the cookie is not strictly necessary, you may opt in or out of cookie use at any time. To alter the way in which we collect information from you, visit our Cookie Manager.
A cookie is a small file with information that your browser stores on your device. Information in this file is typically shared with the owner of the site in addition to potential partners and third parties to that business. The collection of this information may be used in the function of the site and/or to improve your experience.
So long as the cookie is not strictly necessary, you may opt in or out of cookie use at any time. To alter the way in which we collect information from you, visit our Cookie Manager.
We will only retain your Personal Data for as long as necessary for the purpose for which that data was collected and to the extent required by applicable law. When we no longer need Personal Data, we will remove it from our systems and/or take steps to anonymize it.
If we are involved in a merger, acquisition or asset sale, your personal information may be transferred. We will provide notice before your personal information is transferred and becomes subject to a different Privacy Policy. Under certain circumstances, we may be required to disclose your personal information if required to do so by law or in response to valid requests by public authorities (e.g. a court or a government agency).
We have appropriate organizational safeguards and security measures in place to protect your Personal Data from being accidentally lost, used or accessed in an unauthorized way, altered or disclosed. The communication between your browser and our website uses a secure encrypted connection wherever your Personal Data is involved. We require any third party who is contracted to process your Personal Data on our behalf to have security measures in place to protect your data and to treat such data in accordance with the law. In the unfortunate event of a Personal Data breach, we will notify you and any applicable regulator when we are legally required to do so.
We do not knowingly collect Personal Data from children under the age of 18 Years.
Depending on your geographical location and citizenship, your rights are subject to local data privacy regulations. These rights may include:
Right to Access (PIPEDA, GDPR Article 15, CCPA/CPRA, CPA, VCDPA, CTDPA, UCPA, LGPD, POPIA)
You have the right to learn whether we are processing your Personal Data and to request a copy of the Personal Data we are processing about you.
Right to Rectification (PIPEDA, GDPR Article 16, CPRA, CPA, VCDPA, CTDPA, LGPD, POPIA)
You have the right to have incomplete or inaccurate Personal Data that we process about you rectified.
Right to be Forgotten (right to erasure) (GDPR Article 17, CCPA/CPRA, CPA, VCDPA, CTDPA, UCPA, LGPD, POPIA)
You have the right to request that we delete Personal Data that we process about you, unless we need to retain such data in order to comply with a legal obligation or to establish, exercise or defend legal claims.
Right to Restriction of Processing (GDPR Article 18, LGPD)
You have the right to restrict our processing of your Personal Data under certain circumstances. In this case, we will not process your Data for any purpose other than storing it.
Right to Portability (PIPEDA, GDPR Article 20, LGPD)
You have the right to obtain Personal Data we hold about you, in a structured, electronic format, and to transmit such Personal Data to another data controller, where this is (a) Personal Data which you have provided to us, and (b) if we are processing that data on the basis of your consent or to perform a contract with you or the third party that subscribes to services.
Right to Opt Out (CPRA, CPA, VCDPA, CTDPA, UCPA)
You have the right to opt out of the processing of your Personal Data for purposes of: (1) Targeted advertising; (2) The sale of Personal Data; and/or (3) Profiling in furtherance of decisions that produce legal or similarly significant effects concerning you. Under CPRA, you have the right to opt out of the sharing of your Personal Data to third parties and our use and disclosure of your Sensitive Personal Data to uses necessary to provide the products and services reasonably expected by you.
Right to Objection (GDPR Article 21, LGPD, POPIA)
Where the legal justification for our processing of your Personal Data is our legitimate interest, you have the right to object to such processing on grounds relating to your particular situation. We will abide by your request unless we have compelling legitimate grounds for processing which override your interests and rights, or if we need to continue to process the Personal Data for the establishment, exercise or defense of a legal claim.
Nondiscrimination and nonretaliation (CCPA/CPRA, CPA, VCDPA, CTDPA, UCPA)
You have the right not to be denied service or have an altered experience for exercising your rights.
File an Appeal (CPA, VCDPA, CTDPA)
You have the right to file an appeal based on our response to you exercising any of these rights. In the event you disagree with how we resolved the appeal, you have the right to contact the attorney general located here:
If you are based in Colorado, please visit this website to file a complaint. If you are based in Virginia, please visit this website to file a complaint. If you are based in Connecticut, please visit this website to file a complaint.
File a Complaint (GDPR Article 77, LGPD, POPIA)
You have the right to bring a claim before their competent data protection authority. If you are based in the EEA, please visit this website (http://ec.europa.eu/newsroom/article29/document.cfm?action=display&doc_id=50061) for a list of local data protection authorities.
If you have consented to our processing of your Personal Data, you have the right to withdraw your consent at any time, free of charge, such as where you wish to opt out from marketing messages that you receive from us. If you wish to withdraw your consent, please contact us using the information found at the bottom of this page.
You can make a request to exercise any of these rights in relation to your Personal Data by sending the request to our privacy team by using the form below.
For your own privacy and security, at our discretion, we may require you to prove your identity before providing the requested information.
We may modify this Policy at any time. If we make changes to this Policy then we will post an updated version of this Policy at this website. When using our services, you will be asked to review and accept our Privacy Policy. In this manner, we may record your acceptance and notify you of any future changes to this Policy.
To request a copy for your information, unsubscribe from our email list, request for your data to be deleted, or ask a question about your data privacy, we've made the process simple:
Our aim is to keep this Agreement as readable as possible, but in some cases for legal reasons, some of the language is required "legalese".
These terms of service are entered into by and between You and Scry Analytics, Inc., ("Company," "we," "our," or "us"). The following terms and conditions, together with any documents they expressly incorporate by reference (collectively "Terms of Service"), govern your access to and use of www.scryai.com, including any content, functionality, and services offered on or through www.scryai.com (the "Website").
Please read the Terms of Service carefully before you start to use the Website.
By using the Website [or by clicking to accept or agree to the Terms of Service when this option is made available to you], you accept and agree to be bound and abide by these Terms of Service and our Privacy Policy, found at Privacy Policy, incorporated herein by reference. If you do not want to agree to these Terms of Service, you must not access or use the Website.
Accept and agree to be bound and comply with these terms of service. You represent and warrant that you are the legal age of majority under applicable law to form a binding contract with us and, you agree if you access the website from a jurisdiction where it is not permitted, you do so at your own risk.
We may revise and update these Terms of Service from time to time in our sole discretion. All changes are effective immediately when we post them and apply to all access to and use of the Website thereafter.
Continuing to use the Website following the posting of revised Terms of Service means that you accept and agree to the changes. You are expected to check this page each time you access this Website so you are aware of any changes, as they are binding on you.
You are required to ensure that all persons who access the Website are aware of this Agreement and comply with it. It is a condition of your use of the Website that all the information you provide on the Website is correct, current, and complete.
You are solely and entirely responsible for your use of the website and your computer, internet and data security.
You may use the Website only for lawful purposes and in accordance with these Terms of Service. You agree not to use the Website:
The Website and its entire contents, features, and functionality (including but not limited to all information, software, text, displays, images, video, and audio, and the design, selection, and arrangement thereof) are owned by the Company, its licensors, or other providers of such material and are protected by United States and international copyright, trademark, patent, trade secret, and other intellectual property or proprietary rights laws.
These Terms of Service permit you to use the Website for your personal, non-commercial use only. You must not reproduce, distribute, modify, create derivative works of, publicly display, publicly perform, republish, download, store, or transmit any of the material on our Website, except as follows:
You must not access or use for any commercial purposes any part of the website or any services or materials available through the Website.
If you print, copy, modify, download, or otherwise use or provide any other person with access to any part of the Website in breach of the Terms of Service, your right to use the Website will stop immediately and you must, at our option, return or destroy any copies of the materials you have made. No right, title, or interest in or to the Website or any content on the Website is transferred to you, and all rights not expressly granted are reserved by the Company. Any use of the Website not expressly permitted by these Terms of Service is a breach of these Terms of Service and may violate copyright, trademark, and other laws.
The Website may provide you with the opportunity to create, submit, post, display, transmit, public, distribute, or broadcast content and materials to us or in the Website, including but not limited to text, writings, video, audio, photographs, graphics, comments, ratings, reviews, feedback, or personal information or other material (collectively, "Content"). You are responsible for your use of the Website and for any content you provide, including compliance with applicable laws, rules, and regulations.
All User Submissions must comply with the Submission Standards and Prohibited Activities set out in these Terms of Service.
Any User Submissions you post to the Website will be considered non-confidential and non-proprietary. By submitting, posting, or displaying content on or through the Website, you grant us a worldwide, non-exclusive, royalty-free license to use, copy, reproduce, process, disclose, adapt, modify, publish, transmit, display and distribute such Content for any purpose, commercial advertising, or otherwise, and to prepare derivative works of, or incorporate in other works, such as Content, and grant and authorize sublicenses of the foregoing. The use and distribution may occur in any media format and through any media channels.
We do not assert any ownership over your Content. You retain full ownership of all of your Content and any intellectual property rights or other proprietary rights associated with your Content. We are not liable for any statement or representations in your Content provided by you in any area in the Website. You are solely responsible for your Content related to the Website and you expressly agree to exonerate us from any and all responsibility and to refrain from any legal action against us regarding your Content. We are not responsible or liable to any third party for the content or accuracy of any User Submissions posted by you or any other user of the Website. User Submissions are not endorsed by us and do not necessarily represent our opinions or the view of any of our affiliates or partners. We do not assume liability for any User Submission or for any claims, liabilities, or losses resulting from any review.
We have the right, in our sole and absolute discretion, (1) to edit, redact, or otherwise change any Content; (2) to recategorize any Content to place them in more appropriate locations in the Website; and (3) to prescreen or delete any Content at any time and for any reason, without notice. We have no obligation to monitor your Content. Any use of the Website in violation of these Terms of Service may result in, among other things, termination or suspension of your right to use the Website.
These Submission Standards apply to any and all User Submissions. User Submissions must in their entirety comply with all the applicable federal, state, local, and international laws and regulations. Without limiting the foregoing, User Submissions must not:
We have the right, without provision of notice to:
You waive and hold harmless company and its parent, subsidiaries, affiliates, and their respective directors, officers, employees, agents, service providers, contractors, licensors, licensees, suppliers, and successors from any and all claims resulting from any action taken by the company and any of the foregoing parties relating to any, investigations by either the company or by law enforcement authorities.
For your convenience, this Website may provide links or pointers to third-party sites or third-party content. We make no representations about any other websites or third-party content that may be accessed from this Website. If you choose to access any such sites, you do so at your own risk. We have no control over the third-party content or any such third-party sites and accept no responsibility for such sites or for any loss or damage that may arise from your use of them. You are subject to any terms and conditions of such third-party sites.
This Website may provide certain social media features that enable you to:
You may use these features solely as they are provided by us and solely with respect to the content they are displayed with. Subject to the foregoing, you must not:
The Website from which you are linking, or on which you make certain content accessible, must comply in all respects with the Submission Standards set out in these Terms of Service.
You agree to cooperate with us in causing any unauthorized framing or linking immediately to stop.
We reserve the right to withdraw linking permission without notice.
We may disable all or any social media features and any links at any time without notice in our discretion.
You understand and agree that your use of the website, its content, and any goods, digital products, services, information or items found or attained through the website is at your own risk. The website, its content, and any goods, services, digital products, information or items found or attained through the website are provided on an "as is" and "as available" basis, without any warranties or conditions of any kind, either express or implied including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, or non-infringement. The foregoing does not affect any warranties that cannot be excluded or limited under applicable law.
You acknowledge and agree that company or its respective directors, officers, employees, agents, service providers, contractors, licensors, licensees, suppliers, or successors make no warranty, representation, or endorsement with respect to the completeness, security, reliability, suitability, accuracy, currency, or availability of the website or its contents or that any goods, services, digital products, information or items found or attained through the website will be accurate, reliable, error-free, or uninterrupted, that defects will be corrected, that our website or the server that makes it available or content are free of viruses or other harmful components or destructive code.
Except where such exclusions are prohibited by law, in no event shall the company nor its respective directors, officers, employees, agents, service providers, contractors, licensors, licensees, suppliers, or successors be liable under these terms of service to you or any third-party for any consequential, indirect, incidental, exemplary, special, or punitive damages whatsoever, including any damages for business interruption, loss of use, data, revenue or profit, cost of capital, loss of business opportunity, loss of goodwill, whether arising out of breach of contract, tort (including negligence), any other theory of liability, or otherwise, regardless of whether such damages were foreseeable and whether or not the company was advised of the possibility of such damages.
To the maximum extent permitted by applicable law, you agree to defend, indemnify, and hold harmless Company, its parent, subsidiaries, affiliates, and their respective directors, officers, employees, agents, service providers, contractors, licensors, suppliers, successors, and assigns from and against any claims, liabilities, damages, judgments, awards, losses, costs, expenses, or fees (including reasonable attorneys' fees) arising out of or relating to your breach of these Terms of Service or your use of the Website including, but not limited to, third-party sites and content, any use of the Website's content and services other than as expressly authorized in these Terms of Service or any use of any goods, digital products and information purchased from this Website.
At Company’s sole discretion, it may require you to submit any disputes arising from these Terms of Service or use of the Website, including disputes arising from or concerning their interpretation, violation, invalidity, non-performance, or termination, to final and binding arbitration under the Rules of Arbitration of the American Arbitration Association applying Ontario law. (If multiple jurisdictions, under applicable laws).
Any cause of action or claim you may have arising out of or relating to these terms of use or the website must be commenced within 1 year(s) after the cause of action accrues; otherwise, such cause of action or claim is permanently barred.
Your provision of personal information through the Website is governed by our privacy policy located at the "Privacy Policy".
The Website and these Terms of Service will be governed by and construed in accordance with the laws of the Province of Ontario and any applicable federal laws applicable therein, without giving effect to any choice or conflict of law provision, principle, or rule and notwithstanding your domicile, residence, or physical location. Any action or proceeding arising out of or relating to this Website and/or under these Terms of Service will be instituted in the courts of the Province of Ontario, and each party irrevocably submits to the exclusive jurisdiction of such courts in any such action or proceeding. You waive any and all objections to the exercise of jurisdiction over you by such courts and to the venue of such courts.
If you are a citizen of any European Union country or Switzerland, Norway or Iceland, the governing law and forum shall be the laws and courts of your usual place of residence.
The parties agree that the United Nations Convention on Contracts for the International Sale of Goods will not govern these Terms of Service or the rights and obligations of the parties under these Terms of Service.
If any provision of these Terms of Service is illegal or unenforceable under applicable law, the remainder of the provision will be amended to achieve as closely as possible the effect of the original term and all other provisions of these Terms of Service will continue in full force and effect.
These Terms of Service constitute the entire and only Terms of Service between the parties in relation to its subject matter and replaces and extinguishes all prior or simultaneous Terms of Services, undertakings, arrangements, understandings or statements of any nature made by the parties or any of them whether oral or written (and, if written, whether or not in draft form) with respect to such subject matter. Each of the parties acknowledges that they are not relying on any statements, warranties or representations given or made by any of them in relation to the subject matter of these Terms of Service, save those expressly set out in these Terms of Service, and that they shall have no rights or remedies with respect to such subject matter otherwise than under these Terms of Service save to the extent that they arise out of the fraud or fraudulent misrepresentation of another party. No variation of these Terms of Service shall be effective unless it is in writing and signed by or on behalf of Company.
No failure to exercise, and no delay in exercising, on the part of either party, any right or any power hereunder shall operate as a waiver thereof, nor shall any single or partial exercise of any right or power hereunder preclude further exercise of that or any other right hereunder.
We may provide any notice to you under these Terms of Service by: (i) sending a message to the email address you provide to us and consent to us using; or (ii) by posting to the Website. Notices sent by email will be effective when we send the email and notices we provide by posting will be effective upon posting. It is your responsibility to keep your email address current.
To give us notice under these Terms of Service, you must contact us as follows: (i) by personal delivery, overnight courier or registered or certified mail to Scry Analytics Inc. 2635 North 1st Street, Suite 200 San Jose, CA 95134, USA. We may update the address for notices to us by posting a notice on this Website. Notices provided by personal delivery will be effective immediately once personally received by an authorized representative of Company. Notices provided by overnight courier or registered or certified mail will be effective once received and where confirmation has been provided to evidence the receipt of the notice.
To request a copy for your information, unsubscribe from our email list, request for your data to be deleted, or ask a question about your data privacy, we've made the process simple: