
Dr. Alok Aggarwal
Ready to Bring AI Automation to Your Business?
Let's DiscussAlthough a few companies began providing high-end, knowledge-based services from India in 1997, this
trend did not gain momentum until six years later. In September 2003, Evalueserve first coined the term
Knowledge Process Outsourcing (KPO), and in January 2004, I gave a talk at Telcordia Laboratories in
New Jersey that “defined” this industry and provided its growth estimates until 2011. Eventually, the
contents of this talk were summarized in an Evalueserve article titled “The Next Big Opportunity –
Moving Up the Value Chain – From BPO to KPO” that was published on July 13, 2004 [1, 2].
Whereas the processes outsourced (e.g., payroll processing, call center work, and accounting) as a part of
Business Process Outsourcing (BPO) require little domain knowledge, require very few “judgment calls”,
and can be usually executed by someone with a high-school diploma, KPO related work requires deeper
domain knowledge and making “judgment calls” in order to achieve better outcomes. Hence, most
professionals involved in KPO have a post-graduate degree (e.g., MBA, Masters in Law, Masters in Engineering or Computer Science, and Masters or PhD in Pharmaceuticals) and the more work- experience they have in their domain, the better results they can produce. Finally, since the work in KPO is domain related, typically a professional working in one of its sub-domain (e.g., intellectual property) will not be able to work effectively in another domain (e.g., doing research related to gas production).
Since the publishing of the first article on KPO in July 2004 [1], the acronym KPO has become part of the
lexicon of the outsourcing industry worldwide. In addition to the nine articles written by Evalueserve on
this topic, more than two hundred independent articles have been written by others (such as Deloitte
Consulting, TPI, NASSCOM and PwC). Furthermore, there are at least six firms that have KPO as part of
their name; several conferences are held every year on KPO; more than 103 captive units of large
multinational companies are providing KPO services from India to their offices in other countries;
majority of midsized and large IT (Information Technology) and BPO (Business Process Outsourcing)
firms in India have a KPO division; and there are at least 182 “niche” companies in India that provide
third-party KPO services.
Historically, our estimates showed that in 2001, the entire KPO industry in India had only 9,000
professionals who generated approximately USD 260 million in revenue; however, this industry had
already grown to approximately 75,000 professionals by 2007. The Indian KPO sector barely grew
during the great recession of 2008-09 but it is likely to have 166,000 professionals by the end of 2014
who will generate annual revenue of approximately USD 6.21 billion. So, overall, during 2001-2014,
this sector has grown approximately 24 times, i.e., at a compound annual growth rate (CAGR) of 27% – 28%. Finally, during the past 13 years, India has generated approximately 70% of the revenue of the global KPO industry and our models show that India’s preeminence in this field will continue until 2020, and perhaps beyond. Hence, India will continue to be the “king,” nay, the “Emperor” in this area.
Within the KPO industry, some sub-sectors such as investment research and business research
outsourcing services grew very quickly during 2001 and 2007, whereas, others like legal process
outsourcing services grew fairly rapidly during 2006 and 2013 [3]. Various sub-sectors of KPO that were
included in the 2004 article [1] and our current forecasts regarding their growth are given in Figure 1.
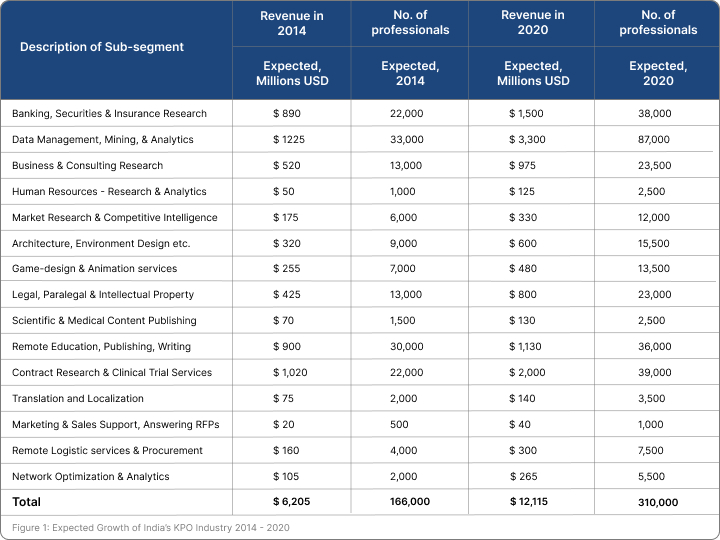
Going forward, our estimates show that overall the KPO outsourcing industry in India is expected to
grow from 166,000 professionals and USD 6.21 billion in revenue in 2014 to 310,000 professionals and
USD 12.12 billion in 2020, which would imply 12% CAGR approximately for the next six years. The
only exception is the sector related to data management, data mining, and analytics, which is expected
to grow from 33,000 professionals and USD 1.23 billion in revenue in 2014 to 87,000 professionals and
USD 3.3 billion in revenue in 2020, thereby implying 18% CAGR. Although an annual growth rate of
18% for the next six years is nothing to sneeze, it is a far cry from the hype that has been created about
such data analytics outsourcing services from India. In the remaining article, we discuss the hype,
myths, and reality related to outsourcing of these data-management related services.
This article is partitioned in five sections. In section 2, we describe the data-information-knowledge
pyramid and the work-flow that is needed to solve various business problems related to analytics. Section 2 also discusses missing gaps in this value chain when it comes to Indian companies. In section 3, we
discuss seven myths related to this sector; for example, we point out that India does not have experienced
analytics professionals that can help in reducing the shortage of experienced analytics professionals in the
United States. Section 4 discusses the potential negative impact of the immigration bill that is pending in
the United States as well as the U.S. government investigations with respect to Infosys and Mu Sigma
regarding potential visa fraud. Finally, Section 5 concludes by stating that since the hype and myths
related to the data analytics outsourcing sector have little connection to reality, these may lead this sector
from boom to bust!
During the last few years, Data Management and Analytics as well as Big Data Science have been often
used interchangeably. Hence, for the sake of completeness, we first define the terms, Big Data and Big
Data Science, and then discuss the workflow and value-chain related to these areas.
The phrase “Big Data” was first coined in 2001 by Doug Laney, a research analyst at Meta Group (now a
part of Gartner) to describe the growth and challenges that are related to data as being three-dimensional,
viz., increasing volume (i.e., amount of data), velocity (i.e., speed of data coming in and going out), and
variety (i.e., range of data types and sources) [4]. In 2012, Laney updated his definition as follows: “Big
data is high volume, high velocity, and/or high variety information assets that require new forms of
processing to enable enhanced decision making, insight discovery and process optimization” [5]. Hence,
unlike traditional analytics, Big Data includes both structured and unstructured data that may be stored in
relational and non-relational databases. Since traditional analytics and business intelligence areas only
handle structured data, Big Data Science is clearly a superset of these areas. In this article, we include all
kinds of data and databases that are related to Big Data Science, which requires the following:
Five key phases in the workflow in Big Data Science for solving a business problem are given below and
can be well understood by using the classical data-information-knowledge pyramid given in Figure 2 [6].
2.1. Data Transformation and Management: Given a specific business problem that needs to be solved, the first and foremost task is to have “good” data that can be used for its analysis. Traditional Extract- Transform-Load (ETL) based approaches push structured data from transactional Enterprise Resource
Planning, Customer Relationship Management and other systems into data warehouses and almost all the
work performed in this regard requires no domain knowledge. Our estimates show that out of 33,000
professionals employed in the data management and analytics outsourcing industry in India today,
approximately 18,000 professionals are employed in the ETL and SQL querying areas who are adept at
handling structured data and doing lower end cleansing work; furthermore, for doing such work, Indian
firms charge between $50,000 and $60,000 per professional per year. However, going forward, given the
characteristics of “Big Data” and the “3Vs” related to it, i.e., volume, velocity, and variety (particularly
with respect to variety related to structured, semi-structured, and unstructured data), our estimates show
that at least two-thirds of all the work in the five phases of this workflow will be actually spent in Big
Data cleansing, munging, wrangling, and harmonizing, which in turn, will depend largely on the domain knowledge of the professionals doing this work. Since most outsourcing companies from India still use
old ETL approaches for data cleansing and do not have domain experts, they run the risk of becoming less
relevant. Furthermore, since these professionals do not have much experience in working with – or in
writing algorithms to cleanse and harmonize – unstructured data, they cannot be used for such intense
data work that is specific to a given domain or a sector.
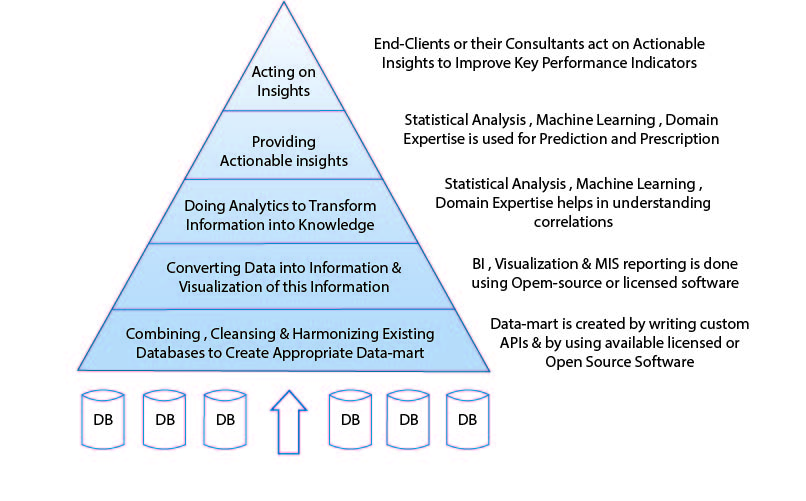
2.2. Descriptive Analytics and Business Intelligence for Converting Data to Information: For a given
business problem, once all of the data has been cleansed, harmonized, and stored in an appropriate
database, descriptive analytics can be done so as to derive and display relevant information. Indeed, by
choosing one of the more than fifty business intelligence software tools, an analyst can display historical
information (e.g., how sales revenue is going up or down for a sales team). Our estimates show that out of
33,000 professionals in this industry in India, approximately 10,000 are employed in business intelligence
(BI) and visualization areas and these professionals typically use Pentaho, Cognos, Business Objects,
Tableau, Qlikview, or home grown solutions that are usually based on Open Source Software. In fact,
more than 80% of the professionals employed by most niche players in India are performing either BI or
ETL activities, and, depending upon their experience, Indian firms charge between $50,000 and $60,000
per professional per year. Again, since these professionals do not have much experience in working with
semi-structured or unstructured data, they cannot be used for displaying such data (e.g., as graphs
containing vertices and edges).
2.3. Predictive Analytics for Providing Knowledge: The next phase in solving a given business problem
is by using predictive analytics, which comprises of statistical and computer science techniques to analyze
cleansed and harmonized data, thereby, gaining knowledge and making predictions about future events.
Our estimates show that out of 33,000 professionals employed in the data management and analytics
industry in India, less than 4,000 are adept at using these techniques, and even in this case, most of them
simply use commercially available software packages (e.g., SAS or SPSS); such professionals are
typically charged at $55,000 to $65,000 per person per year. On the other hand, the Big Data Science
sector is rapidly being transformed by using “R”, Python, and Machine Learning, and therein lays a great chasm that Indian companies need to bridge. Furthermore, for gaining knowledge and making predictions,
Big Data Scientists need to have deep domain knowledge and contextual background of the business
problem being solved, which is by and large non-existent in India.
2.4. Generating Actionable Insights: The fourth phase includes prescriptive analytics and generating actionable insights, thereby, providing decision support. If the data scientists working on a given business problem understand the domain well, they can build and run their analytic algorithms for alternate scenarios in order to improve key performance indicators related to a business problem. Of course,
depending on the domain and the business problem, such key indicators may include increasing revenue
or reducing cost, ensuring compliance, reducing risk, and improving timeliness, quality, and customer
experience. However, given that the Indian analytics industry is quite nascent and there is massive job-
hopping in this industry (Cf. Section 4), out of 33,000 professionals today, there are less than 1,000 data
scientists who have the required math, statistics, and computer science backgrounds and the required
domain expertise to generate such insights. Most such data scientists exist in niche’ firms who have less
than 100 employees that charge $120,000 to $150,000 for each such data scientist per year.
2.5. Acting on the Actionable Insights: The fifth and final phase in this workflow involves acting upon
the actionable insights that were generated in the previous phase. Clearly, this task cannot be done from
India and has to be done onsite either by the end-client or by external consultants used by the client.
During this phase, issues related to correlation versus causation become extremely important and hence
having the required domain knowledge becomes even more critical to the overall success of the project.
Of course, once clients have acted upon these insights, they may embark on one or more business
problems in the same or different areas or they may decide to analyze the same problem on a periodic
basis by using additional internal or external data, in which case, the entire work-flow would be repeated.
A 2011 report from McKinsey Global Institute [7] states that by 2018 in the United States, “demand for
deep analytical positions in big data world could exceed the supply …. by 140,000 to 190,000 positions.
Furthermore, this type of talent is difficult to produce, taking years of training with someone with
intrinsic mathematical abilities…. In addition, we project a need for 1.5 million additional managers and
analysts in the United States who can ask the right questions and consume the results of the analysis of
big data effectively. The United States …. cannot fill this gap by simply changing the graduate
requirements and waiting for people to graduate with more skills or by importing talent…”
In India, since most professionals who have a math, engineering or computer science background end up
joining IT services firm, and since for the next six years, these firms will require approximately 1.2
million new employees, our estimates show that it would be hard for data analytics related areas to attract
and retain more than 54,000 new employees. Hence, the data management and analytics outsourcing
industry in India will be more constrained by the supply of experienced professionals than by the demand
that may exist around the world. Given this backdrop, following are seven myths related to outsourcing of
data analytics services from India:
Myth 1; Shortage of Data Scientists in the U.S can be fulfilled by those in India: According to
Robert Charrete [8], the United States actually produces more than 440,000 graduates and post-graduates
every year in STEM (Science, Technology, Engineering, and Math) areas, and according to the U.S.
Commerce Department, there are 7.6 million professionals working in these areas [8]. However, as per
the McKinsey Global Institute, most of these professionals do not have the experience or expertise to be
Data Scientists and it takes several years to develop these intrinsic capabilities [7]. If the United States is
going to have a shortage of Data Scientists because its professionals either do not have the appropriate
math/computer science skills or the appropriate domain expertise then this problem will be even more
exacerbated in India. Furthermore, since Indian domestic firms are still not using analytics for their own businesses, it is very hard for Indian professionals to leapfrog and acquire the domain expertise regarding
such business problems.
Myth 2; Graduates in India can be converted into Data Scientists by providing 3-6 months of
training: Many firms in India, especially those that are “pure play” firms, have started training their
employees by providing them a three to six months course related to analytics and Big Data Science.
Although such training is laudable and will certainly help in developing this nascent area, it is a far cry
from calling such professionals Big Data Scientists or even experienced analysts. In fact, it is far worse
when these niche firms hype up their training departments and call them “Universities.” Not only is this a
travesty of the Indian education system, it is patently illegal since accreditation from an appropriate
government body is compulsory for all universities except those created by the Indian Parliament [9].
Myth 3; Data Management and Analytics Professionals from India can be charged at almost
the same rates as those in the U.S: Most analytics professionals in India lack mature domain expertise
and they have little experience in high-end statistical techniques (e.g., Bayesian), in artificial intelligence
algorithms or in Python language. Hence, at least for the near future, such professionals will be only
relegated to doing lower end work, thereby, earning the same kinds of salaries as those in other areas of
KPO. Keeping this in view, the end-clients in the U.S. and other developed countries will have to do
substantial due-diligence to see whether an Indian firm has the required domain expertise or if it can only
perform lower end work. And, the best hope for the Indian outsourcing industry is that the managers at
the clients’ end in the U.S. or Europe partition their business problems into sub-problems and the give
these sub-problems to professionals in India, thereby, saving 70% in costs for solving these sub-problems.
Myth 4; Attrition within the Analytics Outsourcing Industry in India is low: Like other sub-
sectors of KPO, attrition in data analytics is approximately 30%, which implies that most data analytics
firms have become “hiring and training machines.” Reasons for higher attrition include late-night working
schedule (which destroys analysts’ work-life balance), boredom with low-end work, and the continued
shortage of such professionals in India. Shortage of such professionals also implies a continued pressure
on wages, thereby, ensuring job-hopping by professionals for a mere wage increase of 15%-20%.
Unfortunately, this shortage will continue for at least the next six years because less than ten universities
and colleges in India are currently offering – or thinking of offering – degrees in this area, which in turn,
is due to an acute shortage of professors in this area. Unfortunately, attrition and “job hopping” further
reduces the acquisition of domain expertise because whenever professionals leave a firm to join another,
they end up learning very little during the last two months of the firm they are leaving and the first two
months of the firm that they are joining.
Myth 5; This time it is different with Data Analytics Outsourcing: In fact, exactly the opposite
is true. Most analytics firms in India are currently following the old beaten path of FTE (Full-Time
Equivalent) pricing and providing these professionals in a staff augmentation mode. Furthermore, like
other sectors of KPO, because there are very few barriers to entry and because the capital requirements of
starting a data analytics firm are very low, there are already more than 180 organizations, which are either
pure-play analytics firms or analytics divisions of larger companies (Cf. Appendix). Clearly, small and
nimble players can keep their overheads (e.g., Sales, General and Administration expenses) low, thereby,
undercutting others and ensuring a race to the bottom with respect to both prices and profit margins.
Hence, just like the other sub-sectors of KPO and ITO, firms in the data analytics sector are already
beginning to witness an LTM-EBITDA (Earnings Before Interest, Taxes, Depreciation and Amortization
for the Last Twelve Months) of 20%-22% with respect to the last twelve months’ (LTM) revenue and this
trend will become even more pronounced in the future.
Myth 6; By creating a few APIs or home-grown visualization software, a Data Analytics
Services company can stand out: In order to differentiate themselves from the pack of the 180 or more analytics companies and divisions in India, several niche companies have started creating “software
macros” or home-grown visualization software. Overall, this seems to be a great move but because there
are already more than 50 visualization software companies in the world, it is not clear that building home-
grown visualization software would help them unless their software is really intuitive and captivating with
a broad appeal. In our view, if the Indian firms really want to differentiate themselves, they would need to
spend significantly more time in developing domain expertise among their professionals or “pivot” their
firms to creating end-to-end solutions.
Myth 7; Valuations for Analytics Outsourcing Companies will be significantly higher than
other KPO companies: Since analytics firms in India are doing low-end analytics work and lack mature
domain expertise, comparison of such companies to Splunk or Palantir seems far-fetched; indeed, Palantir
has deep domain expertise in defense, law enforcement, banking and insurance sectors, whereas, Splunk
has deep expertise in “machine data” that is being generated by “Internet of Things”. Also, according to
our estimates, most KPO companies in India are likely to grow at approximately 12% CAGR for the next
six years and their current valuation would be around 11 to 12 times LTM-EBITDA. Hence, it is hard to
see how the corresponding valuation for the corresponding data analytics services firms in India would be
more than 16-18 times LTM-EBITDA, especially when they are likely to grow at 18% CAGR (for the
next six years).
The Immigration Reform Bill that is pending in the United States and that may be taken up sometime in
2015 has the following clauses, which may have a more pronounced effect for data analytics outsourcing
firms than those providing IT outsourcing, BPO and other KPO services:
Since Data Analytics and Big Data Science area requires most managers and analysts to be onsite (for
understanding the business problem and working with associated data), the above mentioned pending
immigration bill and the following investigations by the U.S. Government with respect to Infosys and Mu
Sigma for visa fraud may cast a dark shadow on this area.
In 2011, the United States Government accused Infosys of using workers with a B-1 visa (which only
allows temporary entry for business purposes) to perform skilled labor jobs in the United States. The U.S.
Government said that these jobs should have been performed by workers with H1-B or L-1 visas only, the
appropriate visas for foreign nationals to enter the U.S. to perform such skilled jobs. In October 2013,
Infosys eventually entered into a settlement with the U.S. Government to settle allegations of systemic
fraud and abuse of immigration processes and agreed to pay USD 34 million as a penalty [11, 12].
Similarly, in 2014, Mu Sigma confirmed that the U.S. Government is investigating allegations whether
Mu Sigma has engaged in visa fraud. The investigation into Mu Sigma is reminiscent of the one filed
against Infosys mentioned above, and it is not clear as to how this case will turn out [13, 14].
Clearly, the future of the data analytics outsourcing industry in India is bright; however, as discussed
above, the hype and myths around this industry seem to have little – or no connection – to reality, which
may lead this industry from a boom to a bust! Unfortunately, if this industry goes bust then not only will
all data analytics outsourcing firms and their employees suffer, it will also preclude India from becoming
a “Giant” and gain a near “Emperor” status in this area as it has become in the Information Technology
field. According to a recent study by IDC [15], there were 29 million workers in the ICT (Information and
Communication Technology) areas in 2013 out of which 10.4% were present in India, making it the
second largest reservoir of such professionals after the United States of America that has 22% of all such
workers. Such a prowess not only helps India in its domestic and exports IT industry but also helps in
other industries. For example, most experts believe that the reason why Indian scientists were successful
in their first mission of sending a spaceship, Mangalyaan, to Mars for a meagre expense of USD 74
million (whereas Japan and China failed) was mainly due to their IT expertise and the ability to simulate
many required processes on a computer [16].
Blog Written by
CEO, Chief Data Scientist at Scry AI
Author of the book The Fourth Industrial Revolution
and 100 Years of AI (1950-2050)
At Scry Analytics Inc ("us", "we", "our" or the "Company") we value your privacy and the importance of safeguarding your data. This Privacy Policy (the "Policy") describes our privacy practices for the activities set out below. As per your rights, we inform you how we collect, store, access, and otherwise process information relating to individuals. In this Policy, personal data (“Personal Data”) refers to any information that on its own, or in combination with other available information, can identify an individual.
We are committed to protecting your privacy in accordance with the highest level of privacy regulation. As such, we follow the obligations under the below regulations:
This policy applies to the Scry Analytics, Inc. websites, domains, applications, services, and products.
This Policy does not apply to third-party applications, websites, products, services or platforms that may be accessed through (non-) links that we may provide to you. These sites are owned and operated independently from us, and they have their own separate privacy and data collection practices. Any Personal Data that you provide to these websites will be governed by the third-party’s own privacy policy. We cannot accept liability for the actions or policies of these independent sites, and we are not responsible for the content or privacy practices of such sites.
This Policy applies when you interact with us by doing any of the following:
What Personal Data We Collect
When attempt to contact us or make a purchase, we collect the following types of Personal Data:
This includes:
Account Information such as your name, email address, and password
Automated technologies or interactions: As you interact with our website, we may automatically collect the following types of data (all as described above): Device Data about your equipment, Usage Data about your browsing actions and patterns, and Contact Data where tasks carried out via our website remain uncompleted, such as incomplete orders or abandoned baskets. We collect this data by using cookies, server logs and other similar technologies. Please see our Cookie section (below) for further details.
If you provide us, or our service providers, with any Personal Data relating to other individuals, you represent that you have the authority to do so and acknowledge that it will be used in accordance with this Policy. If you believe that your Personal Data has been provided to us improperly, or to otherwise exercise your rights relating to your Personal Data, please contact us by using the information set out in the “Contact us” section below.
When you visit a Scry Analytics, Inc. website, we automatically collect and store information about your visit using browser cookies (files which are sent by us to your computer), or similar technology. You can instruct your browser to refuse all cookies or to indicate when a cookie is being sent. The Help Feature on most browsers will provide information on how to accept cookies, disable cookies or to notify you when receiving a new cookie. If you do not accept cookies, you may not be able to use some features of our Service and we recommend that you leave them turned on.
We also process information when you use our services and products. This information may include:
We may receive your Personal Data from third parties such as companies subscribing to Scry Analytics, Inc. services, partners and other sources. This Personal Data is not collected by us but by a third party and is subject to the relevant third party’s own separate privacy and data collection policies. We do not have any control or input on how your Personal Data is handled by third parties. As always, you have the right to review and rectify this information. If you have any questions you should first contact the relevant third party for further information about your Personal Data.
Our websites and services may contain links to other websites, applications and services maintained by third parties. The information practices of such other services, or of social media networks that host our branded social media pages, are governed by third parties’ privacy statements, which you should review to better understand those third parties’ privacy practices.
We collect and use your Personal Data with your consent to provide, maintain, and develop our products and services and understand how to improve them.
These purposes include:
Where we process your Personal Data to provide a product or service, we do so because it is necessary to perform contractual obligations. All of the above processing is necessary in our legitimate interests to provide products and services and to maintain our relationship with you and to protect our business for example against fraud. Consent will be required to initiate services with you. New consent will be required if any changes are made to the type of data collected. Within our contract, if you fail to provide consent, some services may not be available to you.
Where possible, we store and process data on servers within the general geographical region where you reside (note: this may not be within the country in which you reside). Your Personal Data may also be transferred to, and maintained on, servers residing outside of your state, province, country or other governmental jurisdiction where the data laws may differ from those in your jurisdiction. We will take appropriate steps to ensure that your Personal Data is treated securely and in accordance with this Policy as well as applicable data protection law.Data may be kept in other countries that are considered adequate under your laws.
We will share your Personal Data with third parties only in the ways set out in this Policy or set out at the point when the Personal Data is collected.
We also use Google Analytics to help us understand how our customers use the site. You can read more about how Google uses your Personal Data here: Google Privacy Policy
You can also opt-out of Google Analytics here: https://tools.google.com/dlpage/gaoptout
We may use or disclose your Personal Data in order to comply with a legal obligation, in connection with a request from a public or government authority, or in connection with court or tribunal proceedings, to prevent loss of life or injury, or to protect our rights or property. Where possible and practical to do so, we will tell you in advance of such disclosure.
We may use a third party service provider, independent contractors, agencies, or consultants to deliver and help us improve our products and services. We may share your Personal Data with marketing agencies, database service providers, backup and disaster recovery service providers, email service providers and others but only to maintain and improve our products and services. For further information on the recipients of your Personal Data, please contact us by using the information in the “Contacting us” section below.
A cookie is a small file with information that your browser stores on your device. Information in this file is typically shared with the owner of the site in addition to potential partners and third parties to that business. The collection of this information may be used in the function of the site and/or to improve your experience.
To give you the best experience possible, we use the following types of cookies: Strictly Necessary. As a web application, we require certain necessary cookies to run our service.
We use preference cookies to help us remember the way you like to use our service. Some cookies are used to personalize content and present you with a tailored experience. For example, location could be used to give you services and offers in your area. Analytics. We collect analytics about the types of people who visit our site to improve our service and product.
So long as the cookie is not strictly necessary, you may opt in or out of cookie use at any time. To alter the way in which we collect information from you, visit our Cookie Manager.
A cookie is a small file with information that your browser stores on your device. Information in this file is typically shared with the owner of the site in addition to potential partners and third parties to that business. The collection of this information may be used in the function of the site and/or to improve your experience.
So long as the cookie is not strictly necessary, you may opt in or out of cookie use at any time. To alter the way in which we collect information from you, visit our Cookie Manager.
We will only retain your Personal Data for as long as necessary for the purpose for which that data was collected and to the extent required by applicable law. When we no longer need Personal Data, we will remove it from our systems and/or take steps to anonymize it.
If we are involved in a merger, acquisition or asset sale, your personal information may be transferred. We will provide notice before your personal information is transferred and becomes subject to a different Privacy Policy. Under certain circumstances, we may be required to disclose your personal information if required to do so by law or in response to valid requests by public authorities (e.g. a court or a government agency).
We have appropriate organizational safeguards and security measures in place to protect your Personal Data from being accidentally lost, used or accessed in an unauthorized way, altered or disclosed. The communication between your browser and our website uses a secure encrypted connection wherever your Personal Data is involved. We require any third party who is contracted to process your Personal Data on our behalf to have security measures in place to protect your data and to treat such data in accordance with the law. In the unfortunate event of a Personal Data breach, we will notify you and any applicable regulator when we are legally required to do so.
We do not knowingly collect Personal Data from children under the age of 18 Years.
Depending on your geographical location and citizenship, your rights are subject to local data privacy regulations. These rights may include:
Right to Access (PIPEDA, GDPR Article 15, CCPA/CPRA, CPA, VCDPA, CTDPA, UCPA, LGPD, POPIA)
You have the right to learn whether we are processing your Personal Data and to request a copy of the Personal Data we are processing about you.
Right to Rectification (PIPEDA, GDPR Article 16, CPRA, CPA, VCDPA, CTDPA, LGPD, POPIA)
You have the right to have incomplete or inaccurate Personal Data that we process about you rectified.
Right to be Forgotten (right to erasure) (GDPR Article 17, CCPA/CPRA, CPA, VCDPA, CTDPA, UCPA, LGPD, POPIA)
You have the right to request that we delete Personal Data that we process about you, unless we need to retain such data in order to comply with a legal obligation or to establish, exercise or defend legal claims.
Right to Restriction of Processing (GDPR Article 18, LGPD)
You have the right to restrict our processing of your Personal Data under certain circumstances. In this case, we will not process your Data for any purpose other than storing it.
Right to Portability (PIPEDA, GDPR Article 20, LGPD)
You have the right to obtain Personal Data we hold about you, in a structured, electronic format, and to transmit such Personal Data to another data controller, where this is (a) Personal Data which you have provided to us, and (b) if we are processing that data on the basis of your consent or to perform a contract with you or the third party that subscribes to services.
Right to Opt Out (CPRA, CPA, VCDPA, CTDPA, UCPA)
You have the right to opt out of the processing of your Personal Data for purposes of: (1) Targeted advertising; (2) The sale of Personal Data; and/or (3) Profiling in furtherance of decisions that produce legal or similarly significant effects concerning you. Under CPRA, you have the right to opt out of the sharing of your Personal Data to third parties and our use and disclosure of your Sensitive Personal Data to uses necessary to provide the products and services reasonably expected by you.
Right to Objection (GDPR Article 21, LGPD, POPIA)
Where the legal justification for our processing of your Personal Data is our legitimate interest, you have the right to object to such processing on grounds relating to your particular situation. We will abide by your request unless we have compelling legitimate grounds for processing which override your interests and rights, or if we need to continue to process the Personal Data for the establishment, exercise or defense of a legal claim.
Nondiscrimination and nonretaliation (CCPA/CPRA, CPA, VCDPA, CTDPA, UCPA)
You have the right not to be denied service or have an altered experience for exercising your rights.
File an Appeal (CPA, VCDPA, CTDPA)
You have the right to file an appeal based on our response to you exercising any of these rights. In the event you disagree with how we resolved the appeal, you have the right to contact the attorney general located here:
If you are based in Colorado, please visit this website to file a complaint. If you are based in Virginia, please visit this website to file a complaint. If you are based in Connecticut, please visit this website to file a complaint.
File a Complaint (GDPR Article 77, LGPD, POPIA)
You have the right to bring a claim before their competent data protection authority. If you are based in the EEA, please visit this website (http://ec.europa.eu/newsroom/article29/document.cfm?action=display&doc_id=50061) for a list of local data protection authorities.
If you have consented to our processing of your Personal Data, you have the right to withdraw your consent at any time, free of charge, such as where you wish to opt out from marketing messages that you receive from us. If you wish to withdraw your consent, please contact us using the information found at the bottom of this page.
You can make a request to exercise any of these rights in relation to your Personal Data by sending the request to our privacy team by using the form below.
For your own privacy and security, at our discretion, we may require you to prove your identity before providing the requested information.
We may modify this Policy at any time. If we make changes to this Policy then we will post an updated version of this Policy at this website. When using our services, you will be asked to review and accept our Privacy Policy. In this manner, we may record your acceptance and notify you of any future changes to this Policy.
To request a copy for your information, unsubscribe from our email list, request for your data to be deleted, or ask a question about your data privacy, we've made the process simple:
Our aim is to keep this Agreement as readable as possible, but in some cases for legal reasons, some of the language is required "legalese".
These terms of service are entered into by and between You and Scry Analytics, Inc., ("Company," "we," "our," or "us"). The following terms and conditions, together with any documents they expressly incorporate by reference (collectively "Terms of Service"), govern your access to and use of www.scryai.com, including any content, functionality, and services offered on or through www.scryai.com (the "Website").
Please read the Terms of Service carefully before you start to use the Website.
By using the Website [or by clicking to accept or agree to the Terms of Service when this option is made available to you], you accept and agree to be bound and abide by these Terms of Service and our Privacy Policy, found at Privacy Policy, incorporated herein by reference. If you do not want to agree to these Terms of Service, you must not access or use the Website.
Accept and agree to be bound and comply with these terms of service. You represent and warrant that you are the legal age of majority under applicable law to form a binding contract with us and, you agree if you access the website from a jurisdiction where it is not permitted, you do so at your own risk.
We may revise and update these Terms of Service from time to time in our sole discretion. All changes are effective immediately when we post them and apply to all access to and use of the Website thereafter.
Continuing to use the Website following the posting of revised Terms of Service means that you accept and agree to the changes. You are expected to check this page each time you access this Website so you are aware of any changes, as they are binding on you.
You are required to ensure that all persons who access the Website are aware of this Agreement and comply with it. It is a condition of your use of the Website that all the information you provide on the Website is correct, current, and complete.
You are solely and entirely responsible for your use of the website and your computer, internet and data security.
You may use the Website only for lawful purposes and in accordance with these Terms of Service. You agree not to use the Website:
The Website and its entire contents, features, and functionality (including but not limited to all information, software, text, displays, images, video, and audio, and the design, selection, and arrangement thereof) are owned by the Company, its licensors, or other providers of such material and are protected by United States and international copyright, trademark, patent, trade secret, and other intellectual property or proprietary rights laws.
These Terms of Service permit you to use the Website for your personal, non-commercial use only. You must not reproduce, distribute, modify, create derivative works of, publicly display, publicly perform, republish, download, store, or transmit any of the material on our Website, except as follows:
You must not access or use for any commercial purposes any part of the website or any services or materials available through the Website.
If you print, copy, modify, download, or otherwise use or provide any other person with access to any part of the Website in breach of the Terms of Service, your right to use the Website will stop immediately and you must, at our option, return or destroy any copies of the materials you have made. No right, title, or interest in or to the Website or any content on the Website is transferred to you, and all rights not expressly granted are reserved by the Company. Any use of the Website not expressly permitted by these Terms of Service is a breach of these Terms of Service and may violate copyright, trademark, and other laws.
The Website may provide you with the opportunity to create, submit, post, display, transmit, public, distribute, or broadcast content and materials to us or in the Website, including but not limited to text, writings, video, audio, photographs, graphics, comments, ratings, reviews, feedback, or personal information or other material (collectively, "Content"). You are responsible for your use of the Website and for any content you provide, including compliance with applicable laws, rules, and regulations.
All User Submissions must comply with the Submission Standards and Prohibited Activities set out in these Terms of Service.
Any User Submissions you post to the Website will be considered non-confidential and non-proprietary. By submitting, posting, or displaying content on or through the Website, you grant us a worldwide, non-exclusive, royalty-free license to use, copy, reproduce, process, disclose, adapt, modify, publish, transmit, display and distribute such Content for any purpose, commercial advertising, or otherwise, and to prepare derivative works of, or incorporate in other works, such as Content, and grant and authorize sublicenses of the foregoing. The use and distribution may occur in any media format and through any media channels.
We do not assert any ownership over your Content. You retain full ownership of all of your Content and any intellectual property rights or other proprietary rights associated with your Content. We are not liable for any statement or representations in your Content provided by you in any area in the Website. You are solely responsible for your Content related to the Website and you expressly agree to exonerate us from any and all responsibility and to refrain from any legal action against us regarding your Content. We are not responsible or liable to any third party for the content or accuracy of any User Submissions posted by you or any other user of the Website. User Submissions are not endorsed by us and do not necessarily represent our opinions or the view of any of our affiliates or partners. We do not assume liability for any User Submission or for any claims, liabilities, or losses resulting from any review.
We have the right, in our sole and absolute discretion, (1) to edit, redact, or otherwise change any Content; (2) to recategorize any Content to place them in more appropriate locations in the Website; and (3) to prescreen or delete any Content at any time and for any reason, without notice. We have no obligation to monitor your Content. Any use of the Website in violation of these Terms of Service may result in, among other things, termination or suspension of your right to use the Website.
These Submission Standards apply to any and all User Submissions. User Submissions must in their entirety comply with all the applicable federal, state, local, and international laws and regulations. Without limiting the foregoing, User Submissions must not:
We have the right, without provision of notice to:
You waive and hold harmless company and its parent, subsidiaries, affiliates, and their respective directors, officers, employees, agents, service providers, contractors, licensors, licensees, suppliers, and successors from any and all claims resulting from any action taken by the company and any of the foregoing parties relating to any, investigations by either the company or by law enforcement authorities.
For your convenience, this Website may provide links or pointers to third-party sites or third-party content. We make no representations about any other websites or third-party content that may be accessed from this Website. If you choose to access any such sites, you do so at your own risk. We have no control over the third-party content or any such third-party sites and accept no responsibility for such sites or for any loss or damage that may arise from your use of them. You are subject to any terms and conditions of such third-party sites.
This Website may provide certain social media features that enable you to:
You may use these features solely as they are provided by us and solely with respect to the content they are displayed with. Subject to the foregoing, you must not:
The Website from which you are linking, or on which you make certain content accessible, must comply in all respects with the Submission Standards set out in these Terms of Service.
You agree to cooperate with us in causing any unauthorized framing or linking immediately to stop.
We reserve the right to withdraw linking permission without notice.
We may disable all or any social media features and any links at any time without notice in our discretion.
You understand and agree that your use of the website, its content, and any goods, digital products, services, information or items found or attained through the website is at your own risk. The website, its content, and any goods, services, digital products, information or items found or attained through the website are provided on an "as is" and "as available" basis, without any warranties or conditions of any kind, either express or implied including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, or non-infringement. The foregoing does not affect any warranties that cannot be excluded or limited under applicable law.
You acknowledge and agree that company or its respective directors, officers, employees, agents, service providers, contractors, licensors, licensees, suppliers, or successors make no warranty, representation, or endorsement with respect to the completeness, security, reliability, suitability, accuracy, currency, or availability of the website or its contents or that any goods, services, digital products, information or items found or attained through the website will be accurate, reliable, error-free, or uninterrupted, that defects will be corrected, that our website or the server that makes it available or content are free of viruses or other harmful components or destructive code.
Except where such exclusions are prohibited by law, in no event shall the company nor its respective directors, officers, employees, agents, service providers, contractors, licensors, licensees, suppliers, or successors be liable under these terms of service to you or any third-party for any consequential, indirect, incidental, exemplary, special, or punitive damages whatsoever, including any damages for business interruption, loss of use, data, revenue or profit, cost of capital, loss of business opportunity, loss of goodwill, whether arising out of breach of contract, tort (including negligence), any other theory of liability, or otherwise, regardless of whether such damages were foreseeable and whether or not the company was advised of the possibility of such damages.
To the maximum extent permitted by applicable law, you agree to defend, indemnify, and hold harmless Company, its parent, subsidiaries, affiliates, and their respective directors, officers, employees, agents, service providers, contractors, licensors, suppliers, successors, and assigns from and against any claims, liabilities, damages, judgments, awards, losses, costs, expenses, or fees (including reasonable attorneys' fees) arising out of or relating to your breach of these Terms of Service or your use of the Website including, but not limited to, third-party sites and content, any use of the Website's content and services other than as expressly authorized in these Terms of Service or any use of any goods, digital products and information purchased from this Website.
At Company’s sole discretion, it may require you to submit any disputes arising from these Terms of Service or use of the Website, including disputes arising from or concerning their interpretation, violation, invalidity, non-performance, or termination, to final and binding arbitration under the Rules of Arbitration of the American Arbitration Association applying Ontario law. (If multiple jurisdictions, under applicable laws).
Any cause of action or claim you may have arising out of or relating to these terms of use or the website must be commenced within 1 year(s) after the cause of action accrues; otherwise, such cause of action or claim is permanently barred.
Your provision of personal information through the Website is governed by our privacy policy located at the "Privacy Policy".
The Website and these Terms of Service will be governed by and construed in accordance with the laws of the Province of Ontario and any applicable federal laws applicable therein, without giving effect to any choice or conflict of law provision, principle, or rule and notwithstanding your domicile, residence, or physical location. Any action or proceeding arising out of or relating to this Website and/or under these Terms of Service will be instituted in the courts of the Province of Ontario, and each party irrevocably submits to the exclusive jurisdiction of such courts in any such action or proceeding. You waive any and all objections to the exercise of jurisdiction over you by such courts and to the venue of such courts.
If you are a citizen of any European Union country or Switzerland, Norway or Iceland, the governing law and forum shall be the laws and courts of your usual place of residence.
The parties agree that the United Nations Convention on Contracts for the International Sale of Goods will not govern these Terms of Service or the rights and obligations of the parties under these Terms of Service.
If any provision of these Terms of Service is illegal or unenforceable under applicable law, the remainder of the provision will be amended to achieve as closely as possible the effect of the original term and all other provisions of these Terms of Service will continue in full force and effect.
These Terms of Service constitute the entire and only Terms of Service between the parties in relation to its subject matter and replaces and extinguishes all prior or simultaneous Terms of Services, undertakings, arrangements, understandings or statements of any nature made by the parties or any of them whether oral or written (and, if written, whether or not in draft form) with respect to such subject matter. Each of the parties acknowledges that they are not relying on any statements, warranties or representations given or made by any of them in relation to the subject matter of these Terms of Service, save those expressly set out in these Terms of Service, and that they shall have no rights or remedies with respect to such subject matter otherwise than under these Terms of Service save to the extent that they arise out of the fraud or fraudulent misrepresentation of another party. No variation of these Terms of Service shall be effective unless it is in writing and signed by or on behalf of Company.
No failure to exercise, and no delay in exercising, on the part of either party, any right or any power hereunder shall operate as a waiver thereof, nor shall any single or partial exercise of any right or power hereunder preclude further exercise of that or any other right hereunder.
We may provide any notice to you under these Terms of Service by: (i) sending a message to the email address you provide to us and consent to us using; or (ii) by posting to the Website. Notices sent by email will be effective when we send the email and notices we provide by posting will be effective upon posting. It is your responsibility to keep your email address current.
To give us notice under these Terms of Service, you must contact us as follows: (i) by personal delivery, overnight courier or registered or certified mail to Scry Analytics Inc. 2635 North 1st Street, Suite 200 San Jose, CA 95134, USA. We may update the address for notices to us by posting a notice on this Website. Notices provided by personal delivery will be effective immediately once personally received by an authorized representative of Company. Notices provided by overnight courier or registered or certified mail will be effective once received and where confirmation has been provided to evidence the receipt of the notice.
To request a copy for your information, unsubscribe from our email list, request for your data to be deleted, or ask a question about your data privacy, we've made the process simple: